
Purpose-Driven Taxonomy Design
In my last post, AI Supported Taxonomy Term Generation, I used an LLM to help generate candidate terms for the revision of a topic taxonomy that had fallen out of sync with the content it was meant to tag. In that example, the taxonomy in question is for the "Insights" articles on my consulting website. Having generated a set of term updates, the next step is now to decide which terms to include and then create an appropriate structure in which to organize them.
You might be thinking, "Great, throw it back into the LLM!" As many folks (among them professional taxonomists) are figuring out, however, with this approach the devil is in the details. An LLM may produce a syntactically correct taxonomy that may conform to reality for a general topic, but you'll have to vet and validate each term to know if that's what it has done. Not only does correcting dodgy output not save you much time, but it also deprives you of the insight you gain by working through goals, options, and implementation mockups yourself.
This article is an overview of what that process looks like. I'll use my Topic Taxonomy revision as a running concrete example and will discuss along the way how these steps scale to larger projects with higher stakes—and more stakeholders. After an introduction to what I mean by "Purpose-Driven Taxonomy Design," I'll discuss:
- Defining taxonomy goals and use cases
- Identifying candidate taxonomy terms
- Defining relationships (creating the taxonomy's structure)
- Moving the work into a spreadsheet to revise and refine
- Vetting the proposed structure and terms
- Migrating the taxonomy to a CMS
Purpose-Driven Design
One common misstep I often see project teams make when beginning a taxonomy initiative is to build a taxonomy "of" a topic rather than "for" a purpose. A taxonomy "of" medical conditions, for instance, instead of a taxonomy "for" locating signs, symptoms, and when to see a physician. Or a taxonomy "of" courses offered, instead of "for" locating programs that align with a student's interests.
You can avoid this trap by first clearly identifying the goals and use cases your taxonomy needs to support, and then ensuring that the structure proposed meets those goals within the technology constraints at hand. This is a process I often follow when creating taxonomies for clients to support mission-critical operations.
While the tools, inputs, and scale needed to develop an enterprise taxonomy will differ from developing the small, low-stakes taxonomy I discuss here, the basic steps can be applied in both instances—and in both cases will usually result in a taxonomy that is more effective and easier to use, maintain, and iterate as your knowledge management needs evolve over time.
Goals & Use Cases
To design a taxonomy for some intended outcome, you need to know what that outcome is. Yes, I know: this feels too obnoxiously obvious to put down in writing. But here we are. I've seen enough cases of organizations skipping this step and ending up frustrated—or worse, feeling that taxonomy "doesn't work"—that I'll risk the annoyance.
In the case of my consulting website topic taxonomy, the goals of the taxonomy are to:
- coordinate content recommendations
- communicate the range of topics I write about
- afford topic-based browsing
- complement site traffic data to show which topics and categories generate the most interest among site visitors
These are the outcomes I want the taxonomy to help me achieve. It's useful to articulate these, and, if there are multiple stakeholders, align on them. Different goals will suggest different structures and terms. I don't need this taxonomy to support faceted browsing, for instance. It's also not a priority (right now) for it to include alternate and non-preferred terms to support search indexing and retrieval.
The use cases of this taxonomy describe how it will be employed to achieve these goals. For this example, my topic taxonomy needs to:
- support the assignment of multiple tags to accurately represent article topics
- support the association of articles that share an identical tag
- support the association of articles that share sibling tags
- support the association of articles that share cousin tags
- support end-user browsing by assigned tags
- support end-user browsing by all tags
For these use cases, associations will be ranked based on how close the relationship between terms is. This means that the specificity of terms should be consistent at different levels of the eventual hierarchy so that terms at similar levels return a predictable number and specificity of results.
Candidate Terms
With a clear sense of why this taxonomy exists and what it needs to accomplish, I can now make informed decisions about which terms to include. In my last article I showed how to use an LLM to generate a ranked list of candidate terms for a collection of content. I'll narrow this list down by choosing terms that are most likely to help me meet the goals defined above for the intended audience of the content and the purpose of the site as a whole.
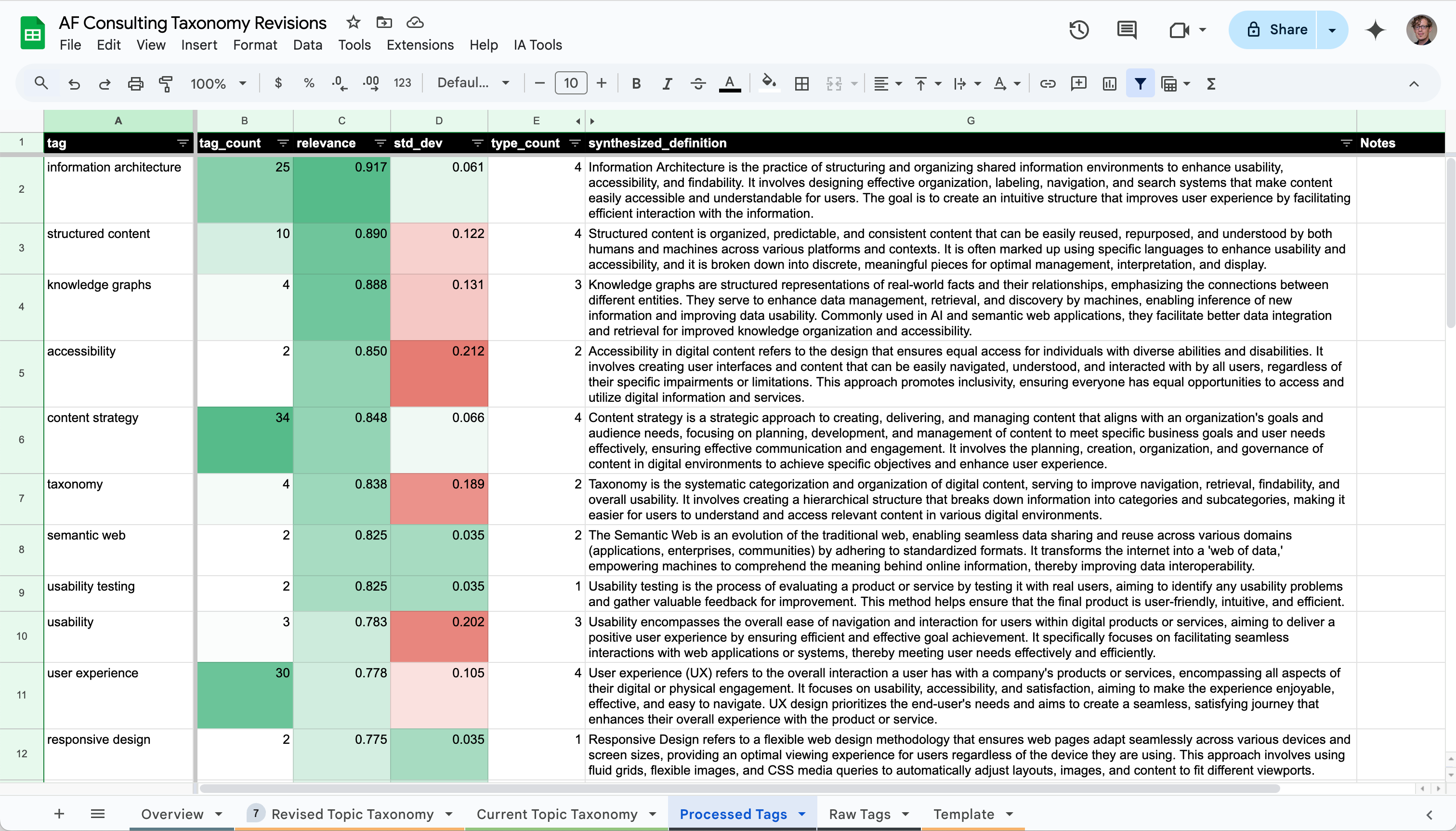
Each term returned from the term generation process includes data for:
- the number of resources to which it was applied
- the average relevance score of the tag to its content
- the standard deviation of the relevance score
This data allows me to first rank terms by those with the highest average relevance and easily identify those with the lowest standard deviation of relevance scores. This means that for most of the content tagged, the relevance was similarly high.
"Information Architecture," "Content Strategy," and "Semantic Web," for example, all have high relevance scores and low standard deviation. The first two of those terms, however, can be applied to most (if not all) articles in the collection. This doesn't do much to help with the goal of affording topic-based browsing. A category of "all content" doesn't narrow the set down. But they could be good candidate terms for first or second level categories.
Tags with high relevance and a high standard deviation need investigation. By looking at the Raw Tags data returned from the LLM, I can investigate why the range of relevancy scores is broad. For "taxonomy," for instance, two articles have a low score because taxonomy is part of what they discuss, but isn't the main topic of the article. This supports the content recommendation and topic-based browsing goals discussed above.
Some tags, however, like "digital marketing," have a low standard deviation (0.035) and a reasonable measure of relevance (0.75) but are only used twice. These are relatively weak connections between a small set of resources. They also don't align strongly with the site's purpose. I'll likely leave terms like these out of the first draft.
Relationships
Once I have a set of candidate terms, it's time to sort out how they relate to one another. Like the previous step, this one is driven by the goals and use cases defined for the taxonomy, the needs of the site audience, and the purpose of the content collection.
For larger projects with multiple stakeholders and audiences, card sorting with your content set's target audience is a great way to gather evidence for key relationships and structures to consider. Few techniques are as simple to set up and rich in the insights they deliver about users' mental models.
For this small, low-stakes example, sketching structural approaches in a white-boarding tool like Miro is a good way to explore possible options. I started this process by deduplicating concepts and color-coding them into simple categories based on the candidate term selection step. This helped me keep track of where terms originated and how "important" they are to the overall content set.

I then grouped together similar terms, assigning parent terms to groups of similar concepts and explored ways to fit the whole structure together into a single hierarchy.
The approach that initially seemed the most obvious to me was to organize by discipline (Information Architecture, Content Strategy, User Experience Design, etc.), but trying this out quickly showed a problem: many of the tags I had selected belonged in several of these categories at once.
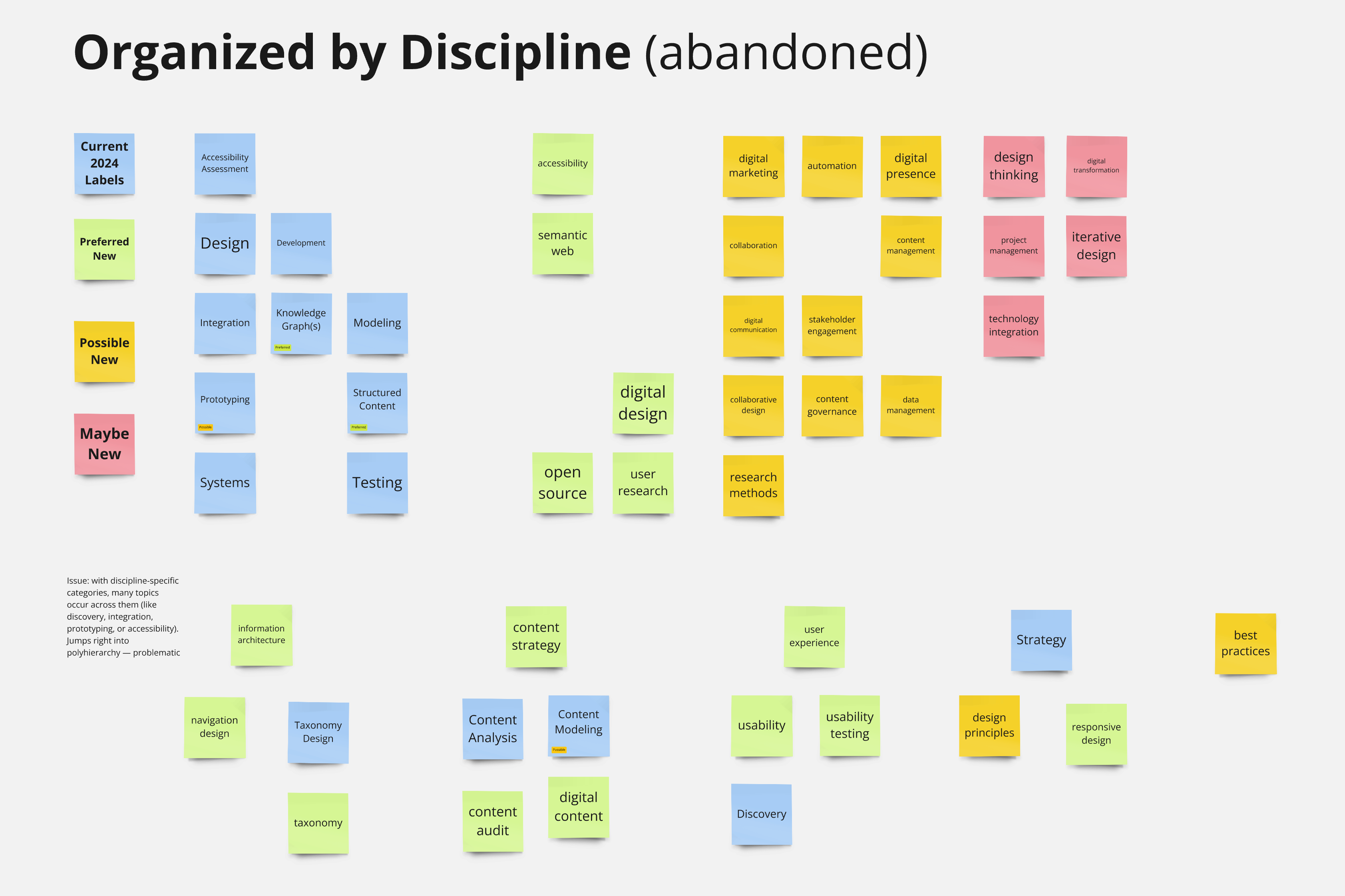
While this arrangement is possible—it's an approach called "polyhierarchy"—it creates a complex set of relationships to manage. Without a compelling reason for the complexity, it's best avoided—particularly as a starting point.
The next approach I tried was to organize terms by "project phase focus." This strategy allowed me to eliminate the polyhierarchy and resulted in a more balanced set of second and third level categories from the start.
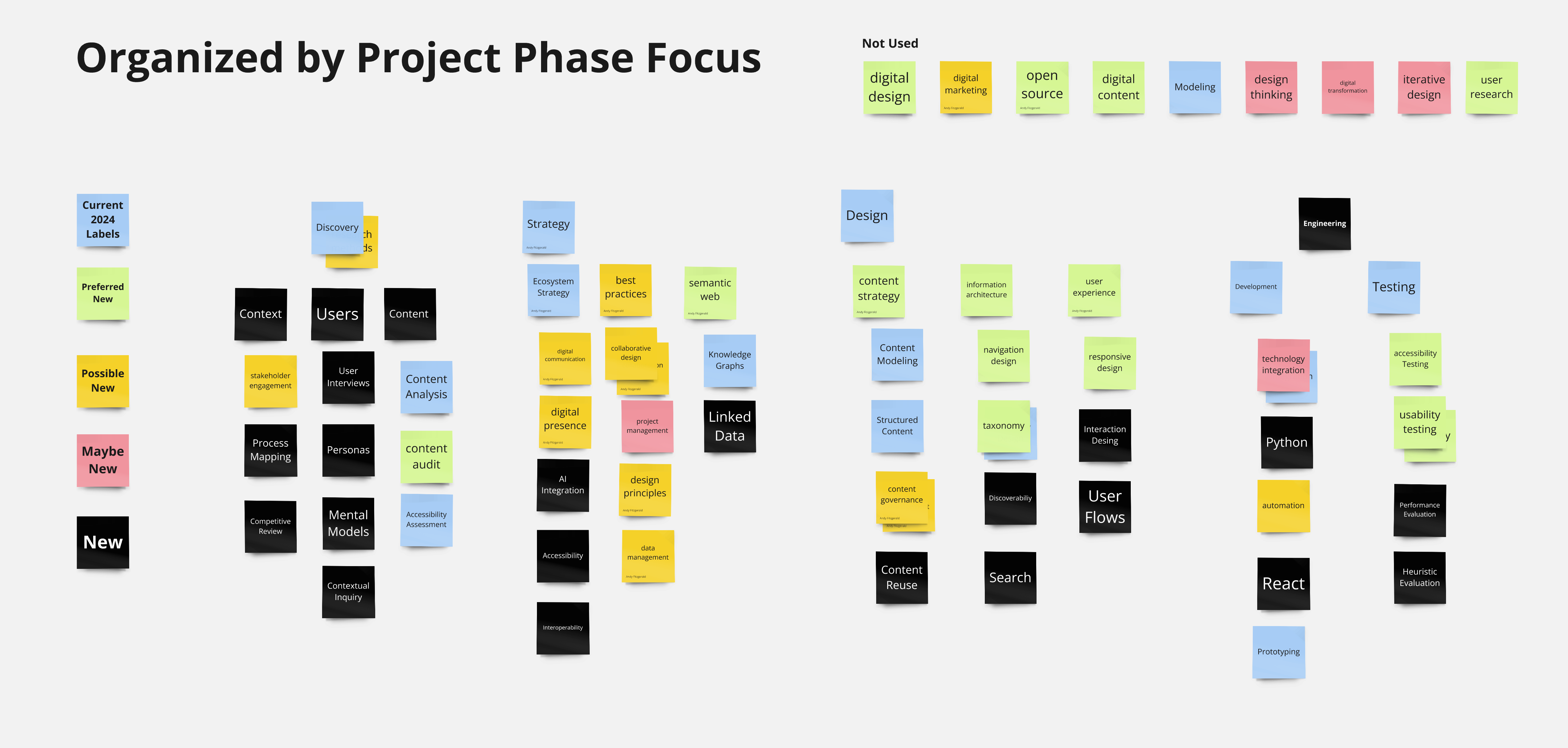
This approach also highlighted gaps in my candidate term set. As I sorted and categorized, I filled in missing concepts from my knowledge of the domain, my content set, my business goals, and my users. These were tags that either provided organizational affordances or weren't currently represented in my content set—but which I could reasonably anticipate would be useful for future articles and case studies.
Though this second structure felt like a good starting point, I explored one more approach to stretch my thinking. This third option uses a "discipline focus by phase" strategy that swaps the first and second level categories.
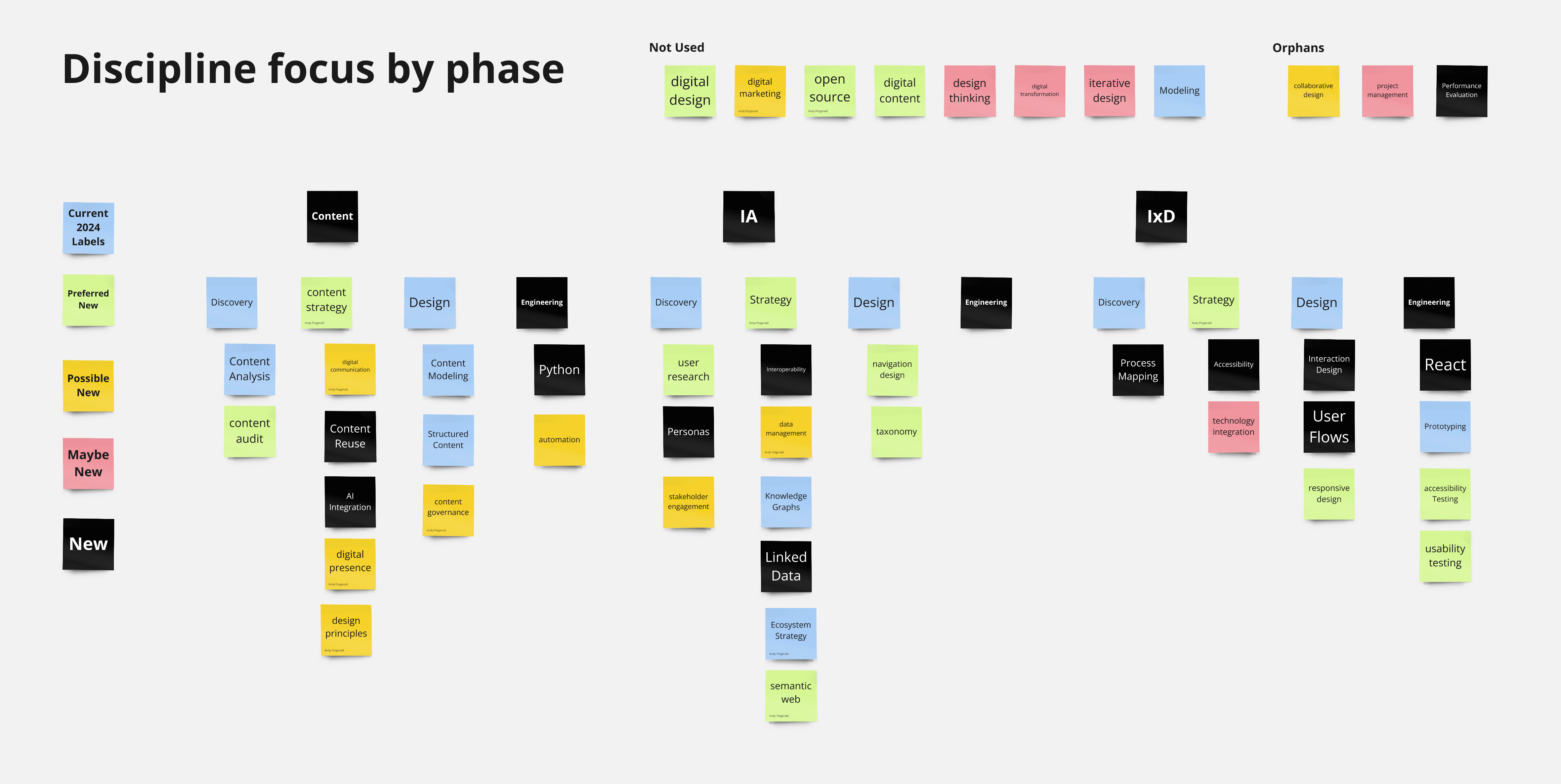
This version isn't the worst thing in the world, but it creates duplication at level two that would require longer (more specified) labels for those terms. It is also less balanced than the "project phase by focus" approach. This would mean that tags in some branches could artificially create more connections than others, just by virtue of their structure.
As neither of these features works to support my goals and use cases, "project phase by focus" is the model I'll move forward with. If you're collaborating with other designers, engineers, or business stakeholders, vetting your selection at this step in a visual tool can be a great way to gather feedback. Virtual whiteboards and sticky notes can be easier for some audiences to handle than spreadsheets—which is where we're heading next.
Define, Revise, and Refine
While digital white-boarding tools like Miro can be a great place to draft structural approaches, the most common tool for revising and vetting a taxonomy is the ubiquitous spreadsheet. Spreadsheets allow you to easily share and iterate your draft, and, if properly formatted, give you a structure you can import into a standards-compliant taxonomy management tool.
A note on "proper formatting": make sure each record (in this case, each taxonomy term) is in its own row. This is a convention I often see skipped, and it makes migrating your structure to a production tool much more complicated than it needs to be. For a primer on data structures for designers, see Tim Sheiner's excellent article "Understanding Data." To make your own blank copy of the spreadsheet I use below, check out the Taxonomy Manager Google Sheets template here.
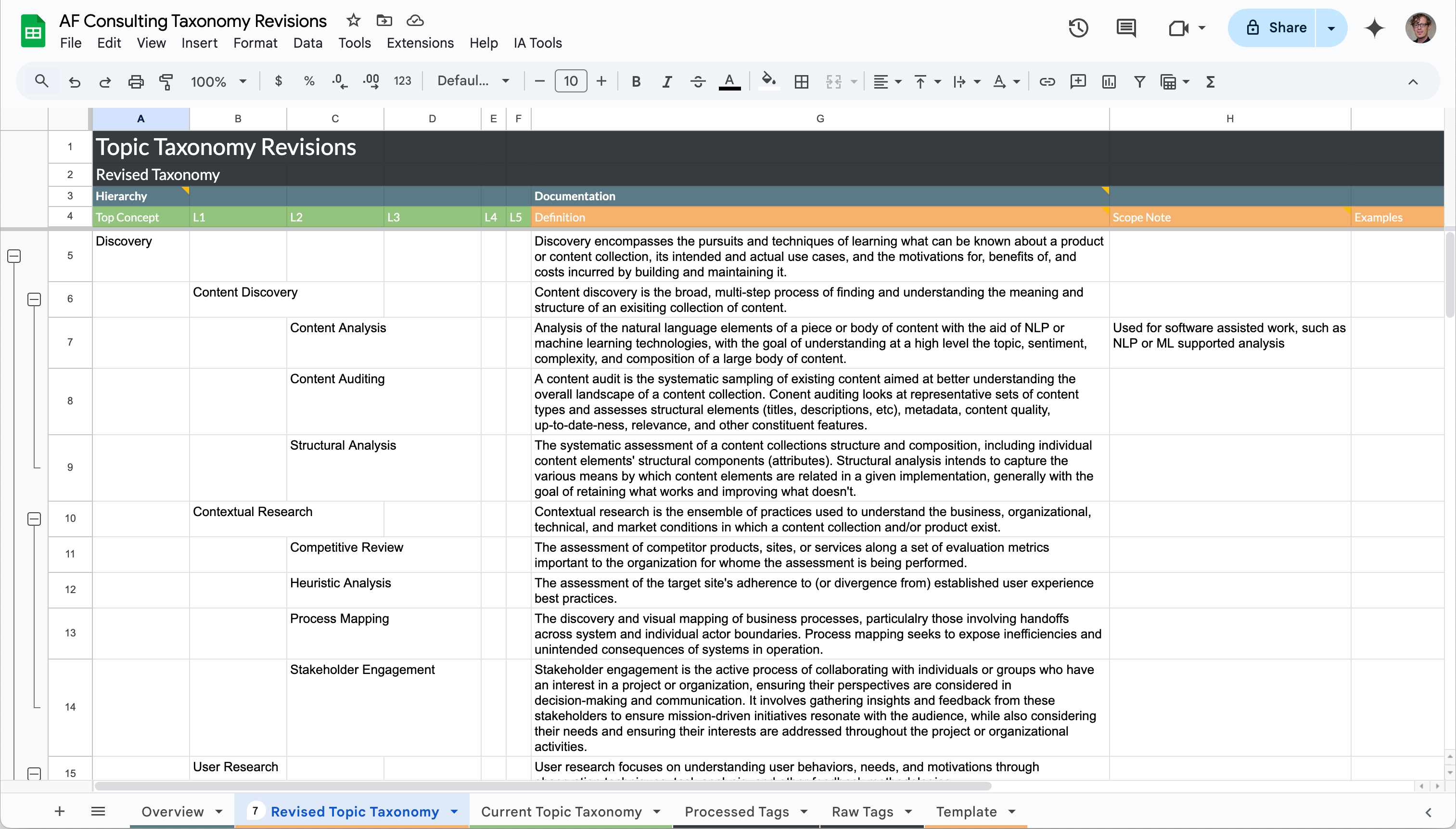
To get my candidate terms into the template, I highlight the relevant set of "sticky notes" in Miro and paste them into the first column. I then organize them into the intended hierarchy and use a VLOOKUP() function in the "Definitions" column to bring over generated definitions from the "Processed Tags" sheet:
=VLOOKUP(C5,'Processed Tags'!A$2:G$39,7,FALSE)
🚨 Do not take these definitions at face value! 🚨
Review, vet, and refine the LLM-generated definitions, and create definitions for any terms you added in the sketching phase. While it's possible to outsource this step to an LLM, the mental activity of creating definitions for this context is a powerful tool for vetting and refining your structure. I find that defining the terms also helps me spot inconsistencies and iterate on the draft approach to create a stronger, more cohesive whole.
This is also a step where, if I'm working with project stakeholders and collaborators, I'll meet with them to get their feedback and input. Even if you're working alone, however, careful attention to the definition phase can help you avoid frustrating errors.
Vet the Proposed Structure
Once you have a revised structure that is coherent, internally consistent, and representative of your goals, test it out against your use cases. As with previous steps, if you're working on a large taxonomy with multiple stakeholders, there are time-tested approaches for getting feedback at scale. Closed card sorting and tree testing are both excellent methods for vetting that a proposed structure is consistent with intended users' mental models.
At a small scale, manual approaches to vetting a structure against use cases can provide an effective sanity check. For the topic taxonomy discussed here, I pulled five recent articles from my website, tagged them with terms from the proposed taxonomy draft, and then traced the connections between the assigned tags based on the association rules outlined in my use cases.
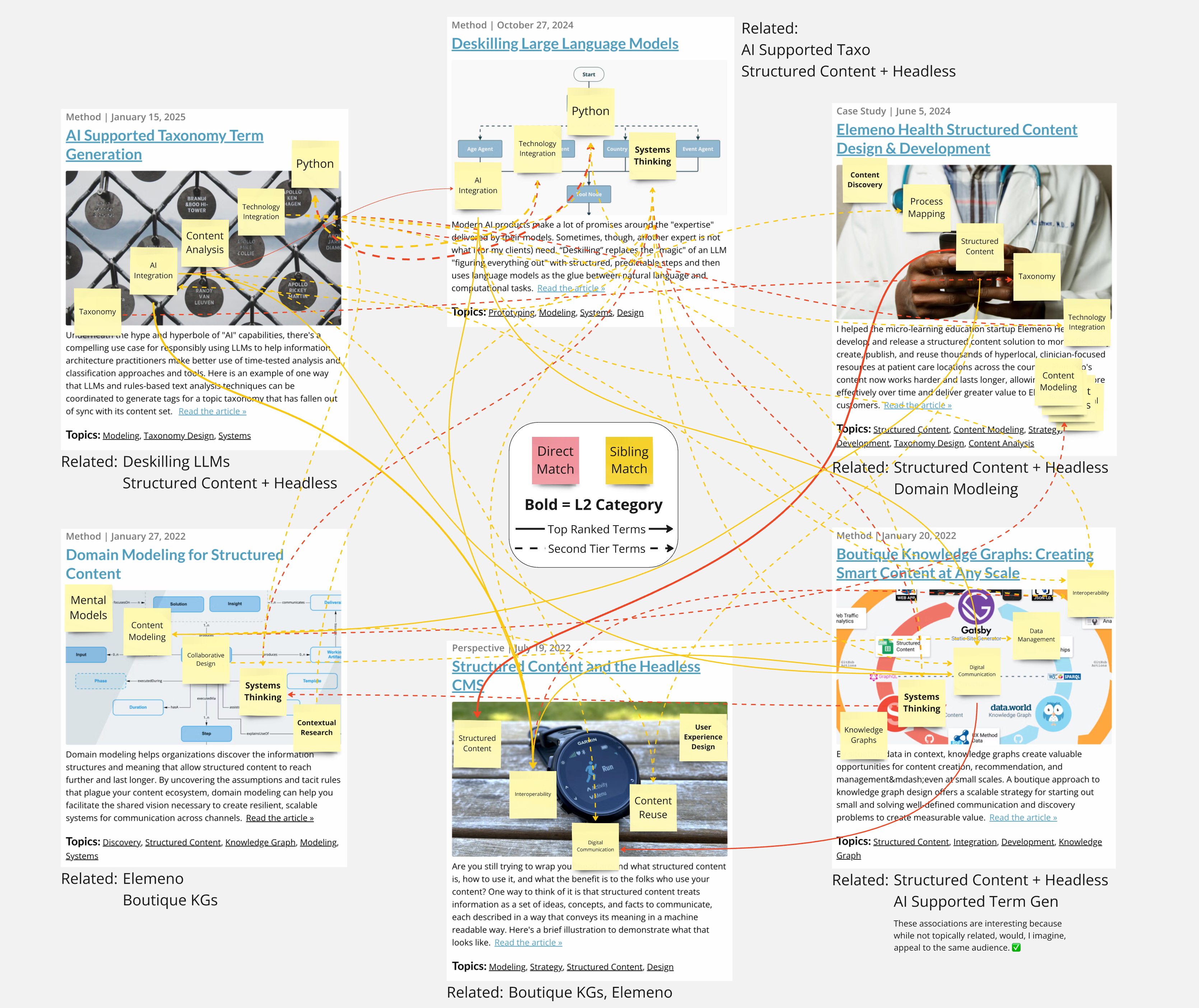
For this exercise, I drew red connectors for tag-to-tag matches and orange connectors for sibling matches. Solid lines represent connections between the first three ranked tags; dashed lines are connections to a lower-priority (less relevant) tag. The result is messy, but it's fast and helps you understand what results your proposed rules and structure will create.
Showing these connections and weights visually allows me to approximate which related articles the tags assigned to a given piece of content are likely to produce. If these are the relationships I expect—or what I would suggest if I were manually connecting content—I'm likely on the right track. If not, I'll return to the model and look for sources of the mismatch.
This is another instance where if you're working with stakeholders or subject matter experts, you'll want to involve them in reviewing, validating, and nuance these findings.
Migrate to the CMS
Now that I've vetted my terms and structure against my use cases and mocked up a sample tagging scenario, I can be reasonably confident that the taxonomy I've created will support the goals I defined at the outset. The true test of a plan, however, is contact with the real world: It's time to migrate the taxonomy to my content management system.
For any but the smallest taxonomies, manually migrating terms can be a tedious and error-prone process. Fortunately, if you've followed a standardized process in creating your structure, migrating terms and relationships to a standards-compliant taxonomy management tool needn't be an ordeal
The spreadsheet template I used to create the topic taxonomy above adheres to the Simple Knowledge Organization System (SKOS) standard established by the World Wide Web Commission (W3C). The taxonomy management tool to which I'll be migrating, the Sanity Studio Taxonomy Manager plug-in (which, coincidentally, I built and maintain), is also SKOS compliant. Thanks to Sanity.io's integration-friendly content store, I can map and upload the entire taxonomy with a single node.js script.
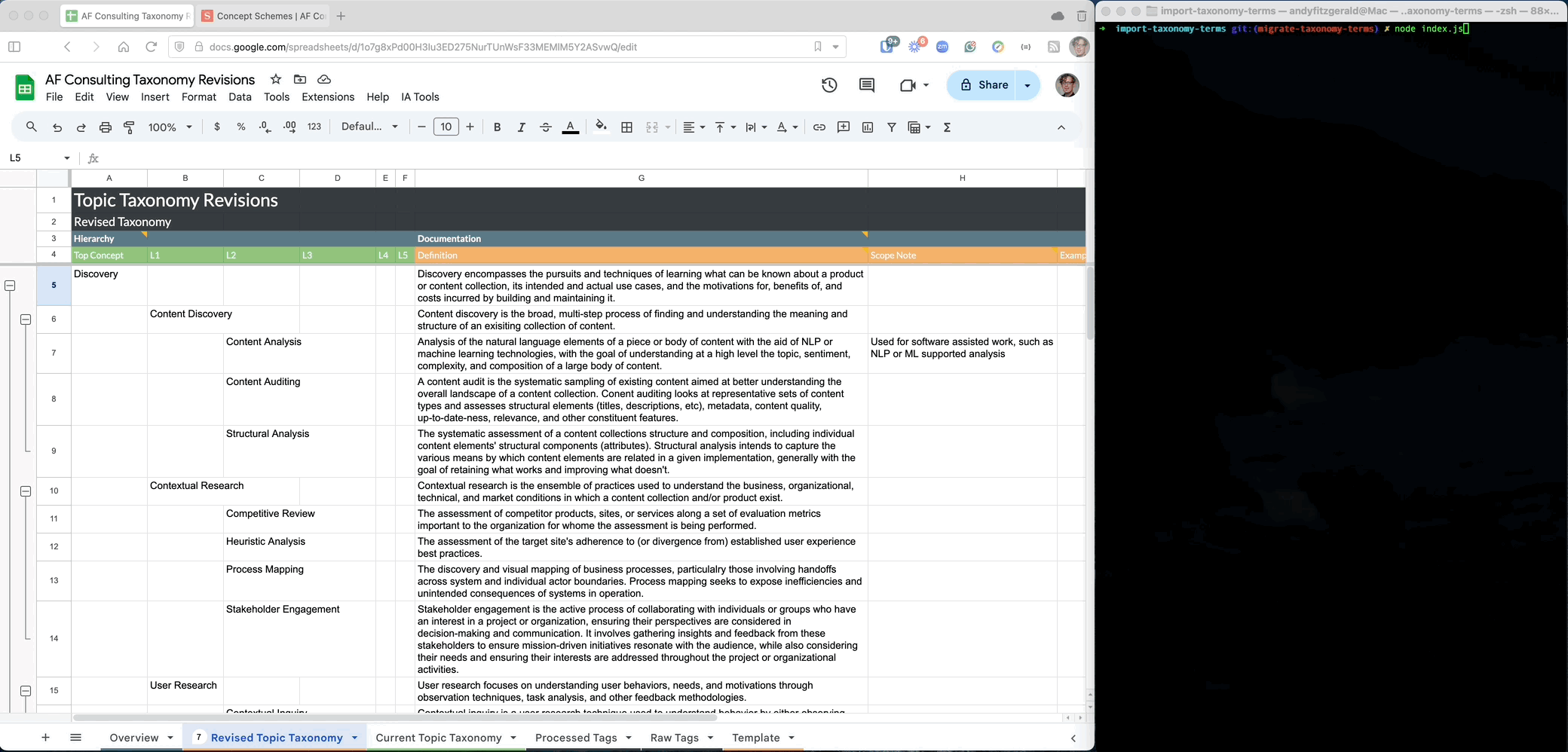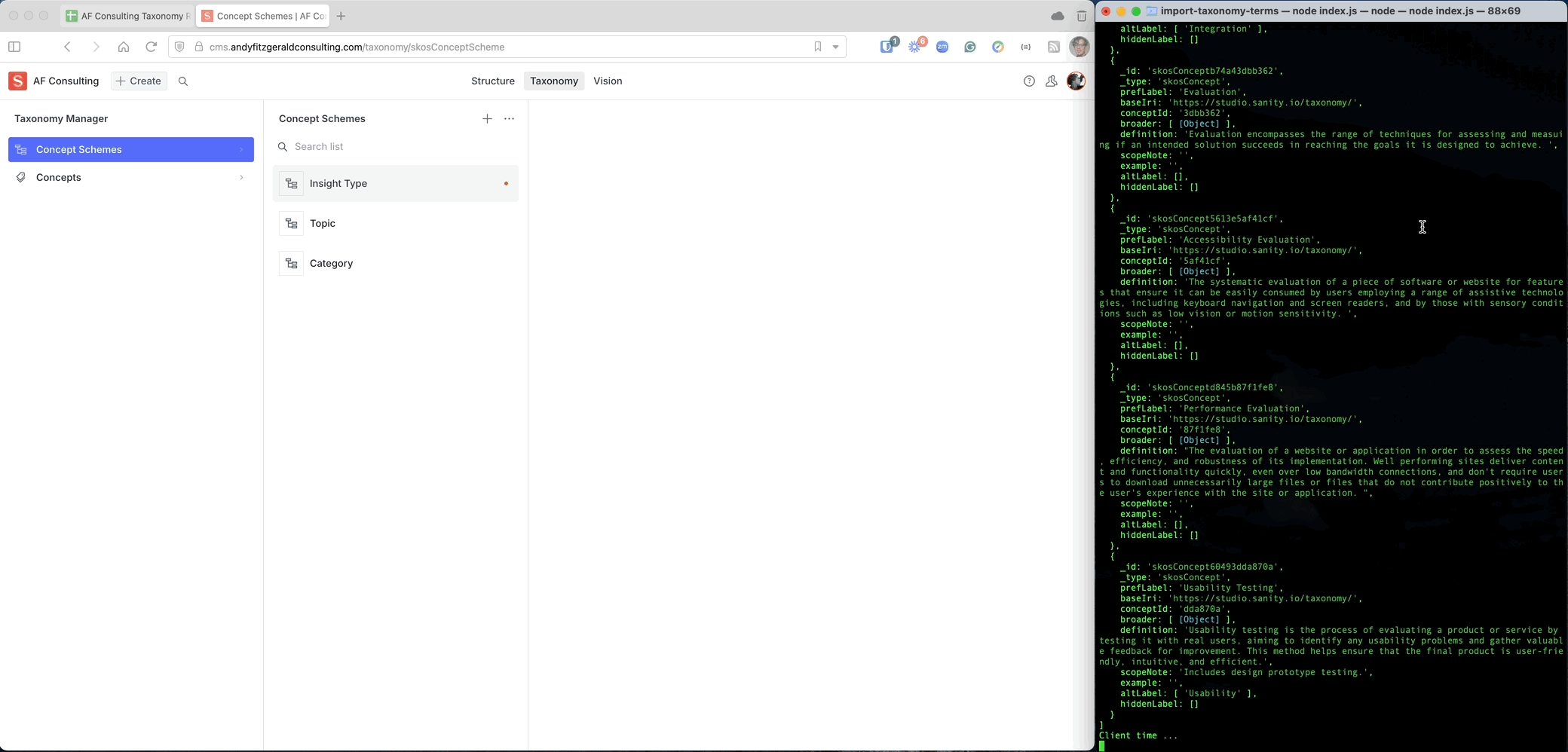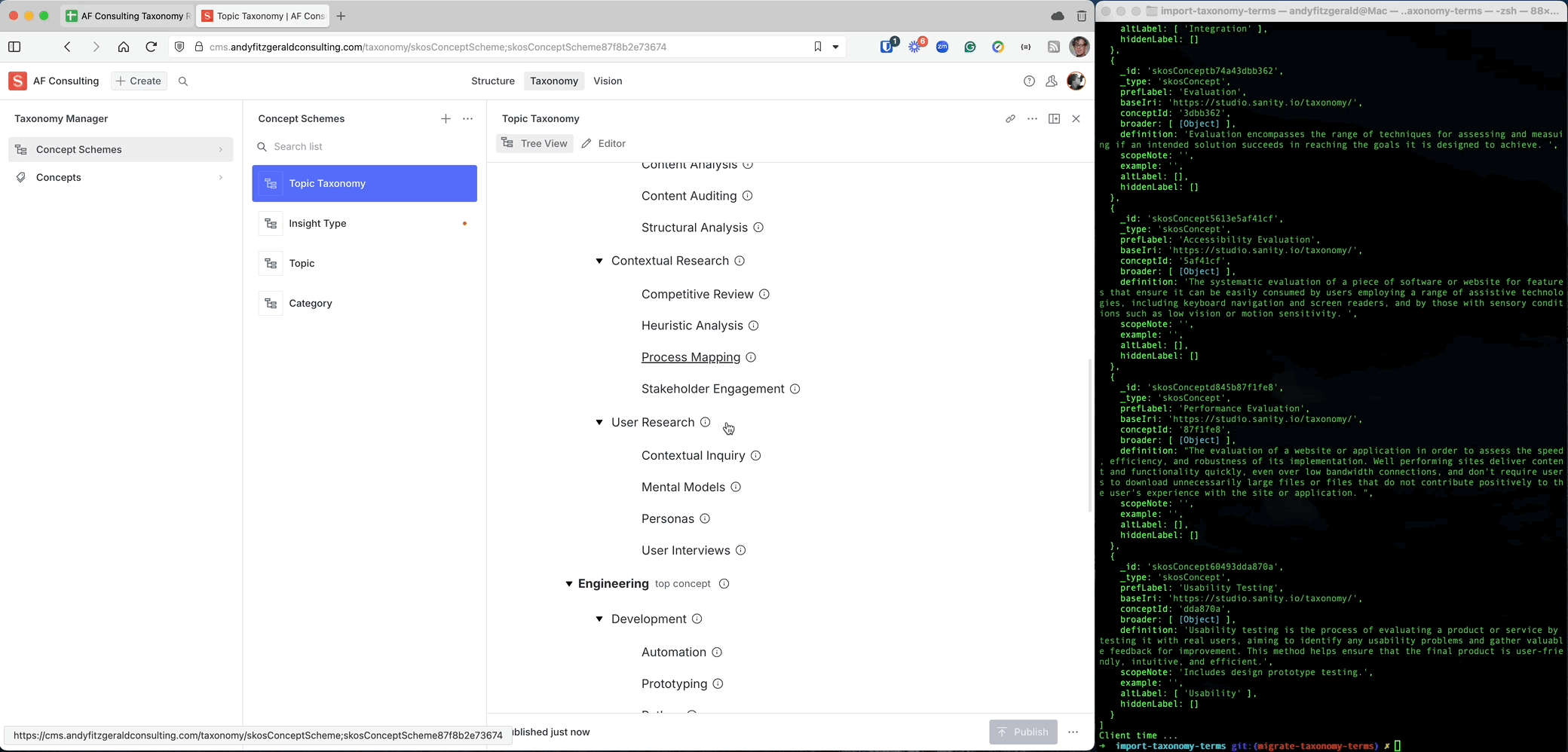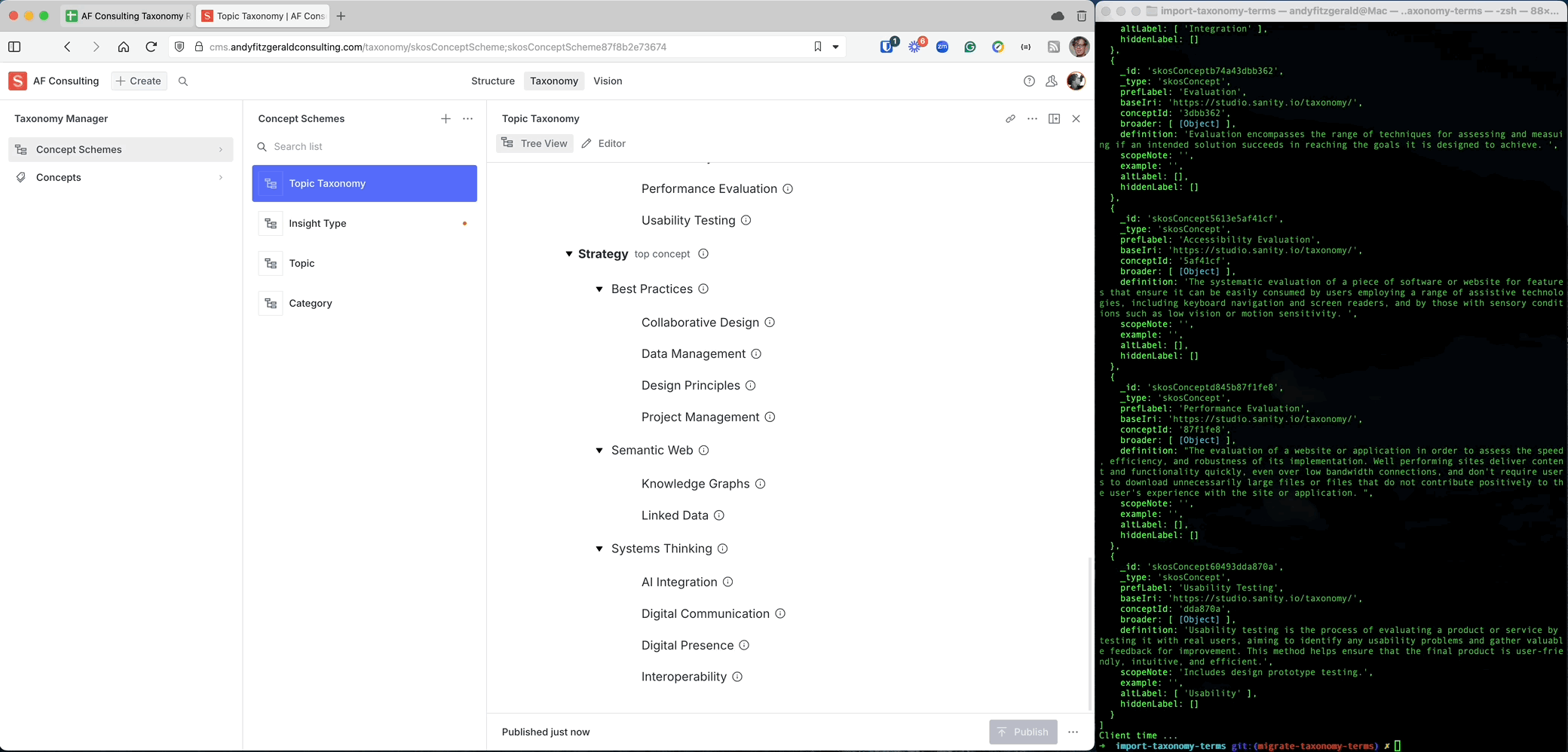
For those of you already using Sanity, I'll share more details on using this script in a follow-up post. If you're using a different CMS—or are evaluating tech stack options—it's well worth researching the degree to which your tools support open standards and free movement between platforms. Just as your taxonomy should be structured (and sized) to support goals that meet clearly defined outcomes, the tools you use to deploy and govern that taxonomy should likewise be chosen to support its scale and interoperability requirements.
Once your taxonomy is integrated with your CMS, the next step, of course, is to start tagging content. In a future post I'll explore some ways you can (responsibly) use LLMs to help with that. I'll also discuss how your structure and term definitions (you are defining your terms, right? 🧐) can help you create consistent, reliable results using purposefully coordinated, resource-appropriate models.