
AI Supported Taxonomy Term Generation
Slowly but surely, "AI" in the form of large language models (LLMs) is becoming a part of my information architecture toolkit. As I've written about elsewhere, I find they're most useful for the kind of IA work I do for my clients when scoped to narrow, specific tasks, often in a workflow with other natural language processing, logic-based reasoning, and human evaluation steps.
A recent experiment I conducted with my consulting website provides an example of what this can look like in practice. Like many websites that have been around for more than a few years (and that may or may not be guilty of a lack of diligence with their governance process 😬), I found that the terms in my topic taxonomy had fallen out of sync with the kinds of topics I now write about.
I could re-read all of my articles, posts, and case studies and manually generate a revised list of candidate topic tags. I have just enough content, however, to make the prospect of going through it piece by piece daunting. I likewise don't sufficiently trust any of the current generation of language models (or "graph rag" systems) to capture the user, content, and business aspects of my taxonomy needs to hand over the task wholesale.
Properly guided and supervised, however, an LLM can be one element of a coordinated toolchain for this task. This article is a walkthrough of one way that chain can be assembled. What follows is a look at:
- information design considerations for toolchain steps
- key toolchain tasks
- results produced & next steps
👉 View the full repo for this workflow on GitHub.
Goal
The goal of this workflow is not to tag content. Free-tagging content and tagging content with existing taxonomy terms are workflows that have already gotten a lot of attention, and there are alreacy many excellent examples of how to accomplish this out there.
I also don't want an LLM to generate a taxonomy for me. A well-designed taxonomy affords a nuanced expression of user needs, business goals, and content focus in a specific context. This requires judgment and accountability. LLMs are notorious for providing answers that look right, but may or may not be garbage. As taxonomists Shannon Moore and Max Gaibort from Electronic Arts so aptly put it in their presentation at Taxonomy Boot Camp in 2024, "taxonomy-shaped responses are not a taxonomy."
I do, however, want a qualified set of candidate terms that could work as entries in my revised taxonomy. "Qualified," in this sense, means those terms that have relevance to my users, content, and business goals ("warrants" in taxonomy lingo), and those that are sufficiently represented across my content collection that they will work to coordinate resources. A tag that only appears once—or can be applied to every resource—is not helpful for discovery, recommendation, or analytics.
A qualified candidate tag should also include a definition and a context-sensitive rationale for why it applies to a particular resource. It should also only occur once in the proposed candidate terms list. This will give the eventual taxonomist (i.e. me) a set of useful inputs with which to make informed decisions about if and how a candidate term fits into the final revised taxonomy.
Workflow Steps
An LLM is clearly a good fit for some of the goals defined above ... and would clearly be rubbish (or wantonly wasteful) for others. I also don't need the same "strength" of LLM for each generative task. Here's the approach I took to coordinate constituent steps so that each is completed with the best tool for the job.
👉 Follow along in the full Notebook here.
1. Fetch & Tidy Articles
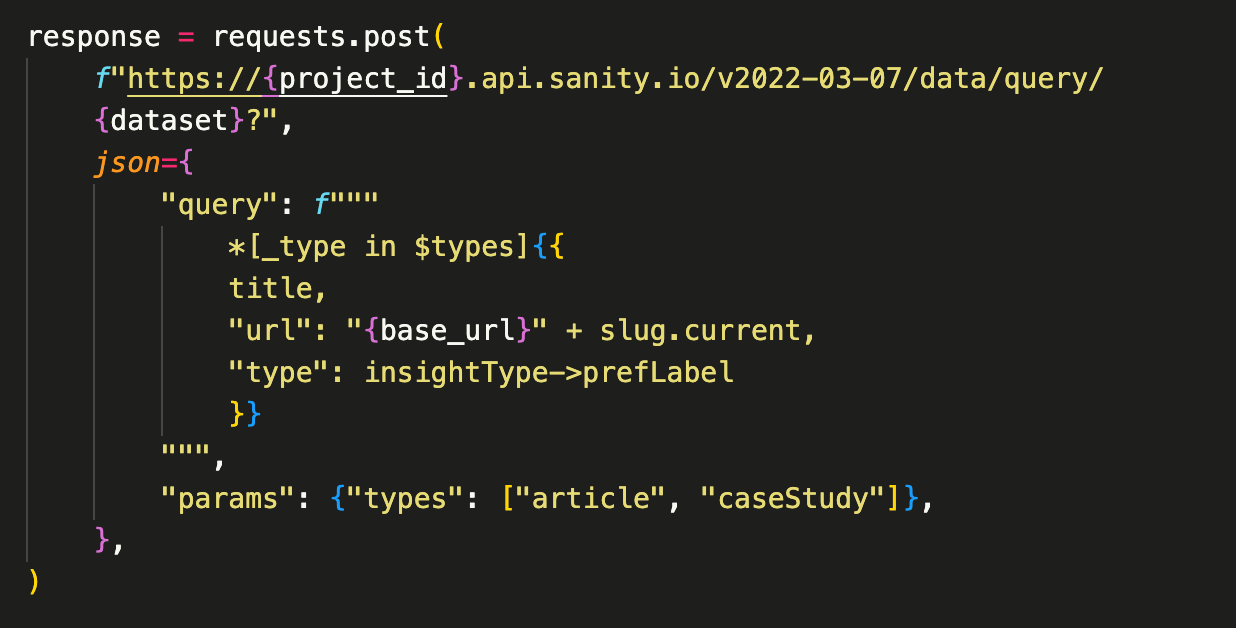
I start by querying my CMS (built with Sanity) for the relevant set of articles that should inform my generated tags. Sanity's "projections" allow me to return just the data I need and format keys to values that will be easy to reference later on.
In this GROQ query, for example, type (sans underscore) is a reference to a term in my site's "types" taxonomy. The GROQ dereferencing operator (->) allows me to return just the preferred label for that term.
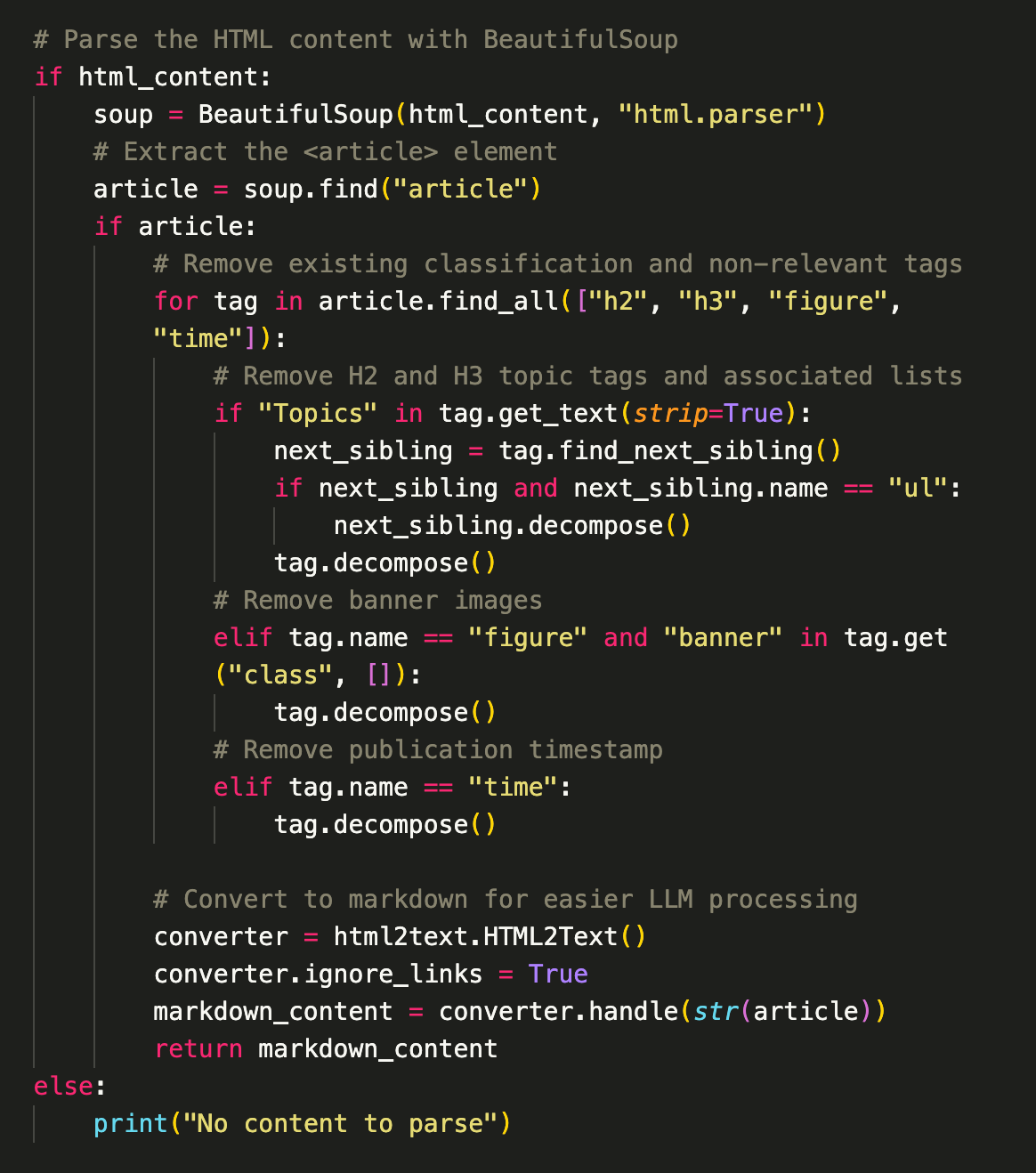
I use Beautiful Soup to strip out decorative headers, timestamps, and existing lists of tags and topics from the returned results. I then convert the HTML to Markdown to make it easier for the LLM to process. This gives the language model a representation similar to what site visitors see when visiting article pages.
All of this content is then added to a Pandas DataFrame. I also add in the word count of each final article, which I'll use later to determine a range for the number of tags the LLM should produce.
2. Create Topic Tag Generation Prompts
Now that I've got the content data I need an accessible format, it's time to give the LLM some guidance. I don't want it to "free tag" this content in the broad sense of the term. My site has a narrow purpose and is intended to speak to a specific audience. I want the LLM to take that into account.
I accomplish this with a system prompt structured into five sections (see the full prompts in the Jupyter Notebook):
- A general overview of what the requested task is and what it will accomplish
- A statement about the purpose of the AF Consulting website
- A concise set of target audience profiles
- The article to be tagged
- A statement describing the grammatical, orthographic, and metadata structure of the tags to be returned
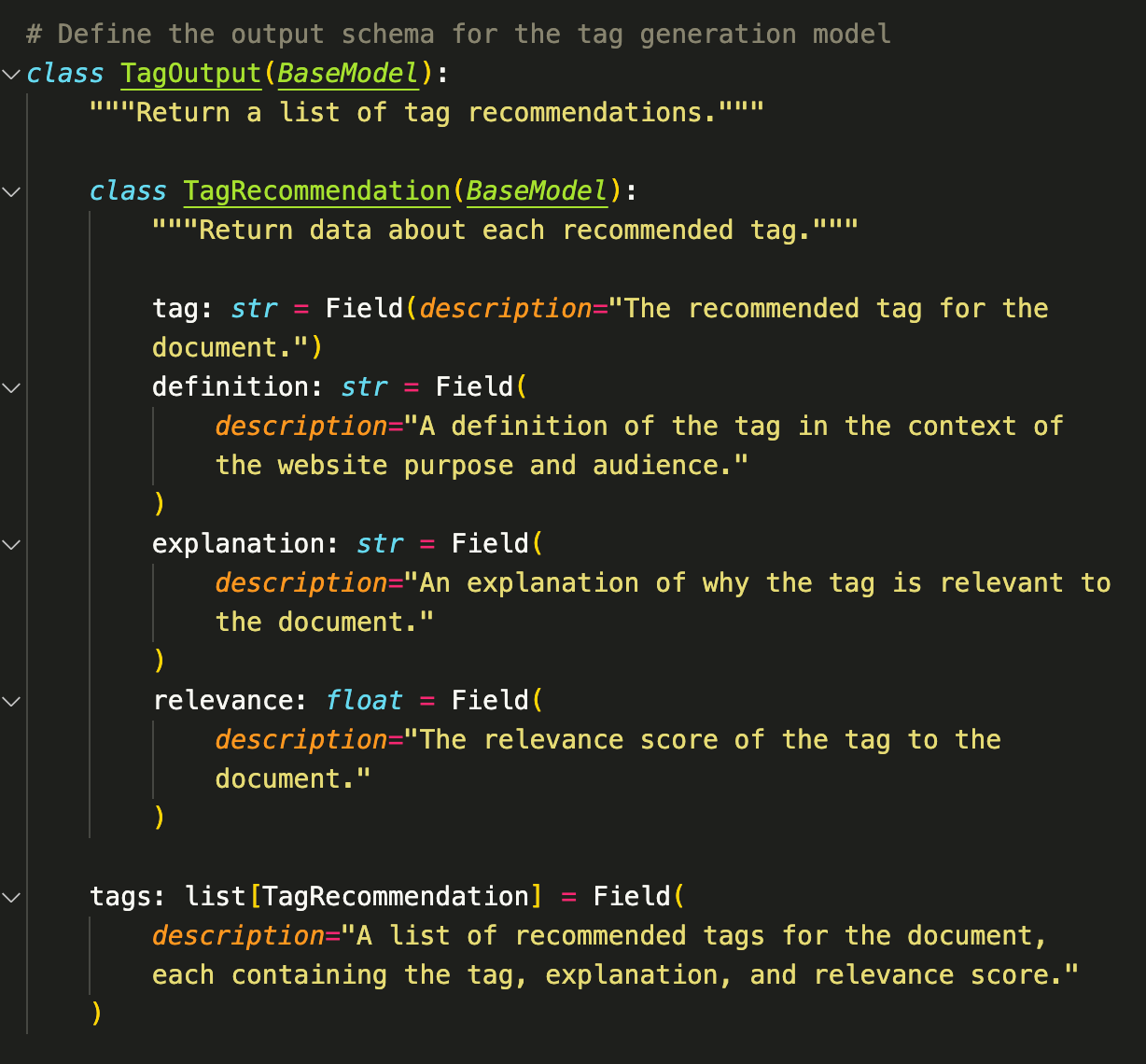
Because this is a relatively complex task with a fairly large input, I've opted for a hosted LLM to carry it out (GPT 4o-mini). For consistency, I also want a model that can enforce structured output. In this case, the model will return a Python dictionary with each output element stored as a value in a predefined structure that I can easily iterate over later.
3. Generate Tags
To generate tags, I loop through the article content in the "articles" DataFrame and submit each with the above prompt to the language model. This step is also where I adjust the number of tags requested based on the length of the article:

To be clear, 10 - 20 tags are far too many tags for any single article. Just as I would request of a human tagger, however, I want the model to exhaust the "obvious" tags and dig for potential outliers. Most of these will be thrown out, but by collecting and reviewing them, I keep the process open to serendipity and the discovery of new ways to describe existing content—or new angles to explore in future articles.
After this expansive pass of tags is generated, I export it as a .csv. This allows me to reuse a copy of this step's output if I need to iterate subsequent steps (and saves on the resource consumption associated with a hosted LLM). It also provides a reference output for the taxonomy authoring work that comes in the next step.
4. Process Tag List
Though useful to generate, the broad take on topic tags generated in the previous step is not the primary input I want to work with when I take a first pass at deciding which tags should be included in the revised taxonomy. Because I've also collected "relevance" scores along the way, I can use this value to filter out low relevance tags that only occur once:
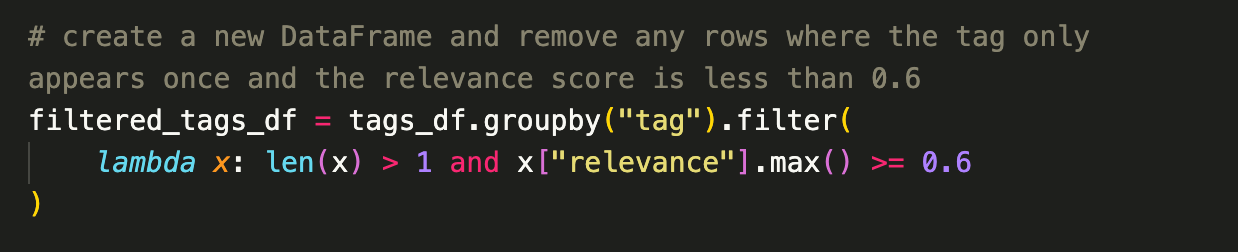
Low-relevance tags that occur in multiple places may have a story to tell, so I'll leave those be.
This step is also where I combine duplicate entries. As you'd imagine, "information architecture" and "content strategy" occur more than once. When deduplicating tags I also calculate a set of stats from the set:
- number of resources tagged
- average "relevance" score
- standard deviation of relevance scores
- number of content types represented
These numbers help me understand at a glance how a particular tag fits with the content set as a whole. I also join together all of the definitions provided (I'll synthesize them in the next step).
5. Synthesize Definitions
Tidying up the concatenated list of definitions created in the last step is another task well-suited to an LLM. Condensing and summarizing verbose content is an area where language models excel—and where humans quickly go crosseyed from the tedium of the work.
This step does not, however, require a high-power hosted LLM. Most of the concatenated definitions are not very long and they mostly repeat the same ideas. By using a smaller model hosted on my MacBook Pro, I can keep the cost and the resource impact of using an LLM to a minimum.

Synthesized definitions are added to a new column in the DataFrame. Unchanged definitions (i.e. for single-entry tags) are passed through to this column for consistency. I then export the trimmed, processed, and synthesized tags as a second .csv for taxonomy development. If anything looks fishy in these final results, I can always refer to the full tag list exported in step three to compare individual entries.
6. Visualize Results
This step isn't strictly necessary, but it's a satisfying wrap-up for the workflow—and the visual representation offers a novel perspective on the generated tag collection as a whole.
For this dataset I've configured a plot to show resource count and relevance score on the x-y axis and standard deviation as a color gradient. The standard deviation metric allows me to quickly identify tags that have the same—or very different—relevance to their respective articles. The size of the point shows the number of content types represented by each tag. Additional data point details are available on hover.

By exporting this final plot as an HTML file, I can preserve the interactive features for later reference.
Results & Next Steps
If you've grown accustomed to the "LLM as one-stop-shop" narratives that often play out on social media, you might be underwhelmed by the output of this process: two .csv files and an interactive chart.
Please recall, however, that the goal of this workflow isn't to create a taxonomy—or attempt to reproduce the judgment calls made by a skilled taxonomist. The goal is to provide a taxonomist with some of the input they need to create an effective vocabulary and help them (in this case, me) minimize the slog of manually reviewing material, exhausting tag options, and defining and rationalizing each candidate tag.
By importing the exported .csv documents into a spreadsheet (taxonomy's natural spawning ground), I've got an informed and annotated set of candidate terms in the environment in which taxonomies invariably take initial shape.

I'm able to quickly see, for instance, which tags are applicable to a majority of my content. I may consider these as top level terms—or may opt to exclude them altogether if they don't do any work to differentiate topics.
The standard deviation of relevance scores likewise helps me identify which tags may have different "strengths" in relation to a given article. In some cases, a parent term may be a better fit. This will inform the structure of the eventual hierarchy.
In the "Raw Tags" tab I can also see which articles had the most "rejected" tags. In this case, that was "A Cognitive Sciences Reading List for Designers," which makes sense as this post covers a dozen topics that inform my practice but which aren't a focus of it.
In a broad sense, these results provide data for an informed revision process that can take shape based on the needs of a particular project. If you're creating a completely new structure, for example, a card sorting exercise with candidate terms may be the right next move. If you're fitting revised terms into an existing structure, drafting the revision based on defined use cases and then tree testing with users might be the right follow-on step.
For this taxonomy, I'll continue with the latter of these two options. I'll discuss my process for that work and for migrating it back into my CMS in a follow-up post. If that piques your interest, stay tuned!