Deskilling Large Language Models
Modern "AI" products make a lot of promises around the "expertise" delivered by their models. And despite one persistent and vexing Achilles heel (i.e. making things up), these tools are getting better with each release.
Sometimes, though, another expert is not what I (or my clients) need. More often, what I really need is a reasonably capable, agreeable, hard-working assistant. More of an "Igor" than a "Dr Frankenstein." After all, I'm usually the one who's been hired to be the expert. In any case, I'm the one who will be held responsible for the quality of the work I deliver, so I have a very real interest in understanding how it is performed.
While it is possible to constrain a language model to be a "lab assistant" through prompting alone, "experts" don't easily fit into "assistant" boxes. Frontier language models are created to generate unique output perceived as "creative." To fight this is to fight with the tool from the start.
Language Model Deskilling
What to do, then, when rather than the latest "AI Expert," what you really need is a reliable, consistent assistant? I've been exploring this question over the last couple of months and have arrived at a process I call "deskilling” language models. Deskilling replaces the "magic" of an LLM "figuring everything out" with structured, predictable steps and then uses language models as the glue between natural language and computational tasks. In the experiments I've run, I've found this to be an effective approach for producing accurate, consistent results using simple, predictable models.
In this article, I'll share an overview of one such exploration and will provide guidelines for how language models can be deskilled for practical purposes along the way. I’ll also provide a set of considerations for steps we might take as information professionals to use language models productively and responsibly in our work.
Why "Deskilling"?
In economics, deskilling is the “process by which skilled labor within an industry or economy is eliminated by the introduction of technologies operated by semi- or unskilled workers." In the Industrial Revolution, for example, the introduction of mechanized looms meant that textile manufacture could be performed by low-wage unskilled labor. This allowed industrialists to push artisan weavers out of the craft and pocket the profits.
Understandably, the artisan weavers were miffed. The ensuing riots over this callous shenanigan are where we get the term “Luddite.” Language models, however, don't have families to support or student loans to pay off. They also don't get bored or angry when you ask them to perform repetitive, tedious, low-level linguistic tasks. Furthermore, if you're a business trying to figure out where and how LLMs created, owned, and operated by other companies fit into your business plan—especially when those companies have unclear and shifting commercial goals—reducing your reliance on the "skill" of a particular model can be a smart way to hedge against risks in what is clearly a very fast moving set of technologies and interests.
As with the deskilling of human labor, when deskilling language models, the complexity of a task must be accounted for in other technologies. One way to accomplish this is through the purposeful orchestration of task composition, granularity, and visibility. These facets allow you to displace the problematic features of language models' so-called "reasoning" capabilities by reducing the complexity and scope of the linguistic tasks performed and coordinating the sequence in which work and decisions are performed.
💼 Let’s unpack that with an example.
A WikiData Olympic Games Agent
Earlier this year, I worked through an experiment of connecting an LLM to Wikidata, the publicly available and collaboratively edited multilingual knowledge graph hosted by the Wikimedia Foundation. I wanted to work through a method of interacting with a real-world knowledge graph that's capable of logically deducing new facts from an existing data store. The goal was to be able to answer questions with logical inferences derived from Wikidata's ontology.
As a test case, I drafted a set of questions about the medalists of the 2024 Summer Olympic Games that would require multi-hop retrieval, logical inference, and the acknowledgment of missing data:
- Who were the youngest medalists at the 2024 Summer Olympics, and what did they win?
- What countries were the youngest medalists at the 2024 Summer Olympics from?
- Who was the youngest medalist from Japan in the 2024 Summer Olympic Games?
- What event in the 2024 Summer Olympics did the youngest medalist from Spain win?
- What medal in the 2024 Summer Olympics did the youngest medalist from Spain win?
- Who was the oldest medalist at the 2024 Olympics from a country in Africa?
- Who was the youngest fencing medalist at the 2024 Olympic Games?
- Who was the oldest medalist in weightlifting at the 2024 Summer Olympics?
The correct responses to these questions are too recent to be in any language model's training data and are not explicitly asserted in the Wikidata corpus. My hypothesis was that a language model could manipulate the parameters of a modular query sent to Wikidata's SPARQL endpoint, which would, in turn, generate a focused set of facts that would ground the LLM's natural language response.
First Test: The Prebuilt LangGraph Agent
I began tests of my WikiData Knowledge Graph hypothesis with a "prebuilt" LangGraph agent, using GPT-4o mini as the underlying language model. LangGraph is a framework for connecting language models and tools in a directed acyclic graph (DAG), which means it affords an opportunity for structural decision points in the way models are connected. It felt like a good place to start.
📘 Conversational Wikidata RAG Agent Notebook (GitHub)
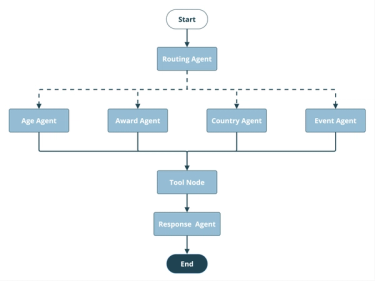
The Prebuilt Agent model works like this:
- A user question is provided at the start node and delivered to the agent
- The agent evaluates the question and makes a decision: answer the question, or consult a "tool." In this case, the tool is a prebuilt modular SPARQL query with verbose descriptions of the available query parameters and what kinds of data it returns
- If a tool response is chosen, the agent formulates and sends the required inputs (the query parameters) to the tool
- The tool executes the query and returns the formatted endpoint response to the agent
- The agent re-evaluates the initial user query in light of the tool response and can decide to formulate a response or re-query the tool
- When a response is finally formulated, the agent calls the end node and delivers the response to the user.
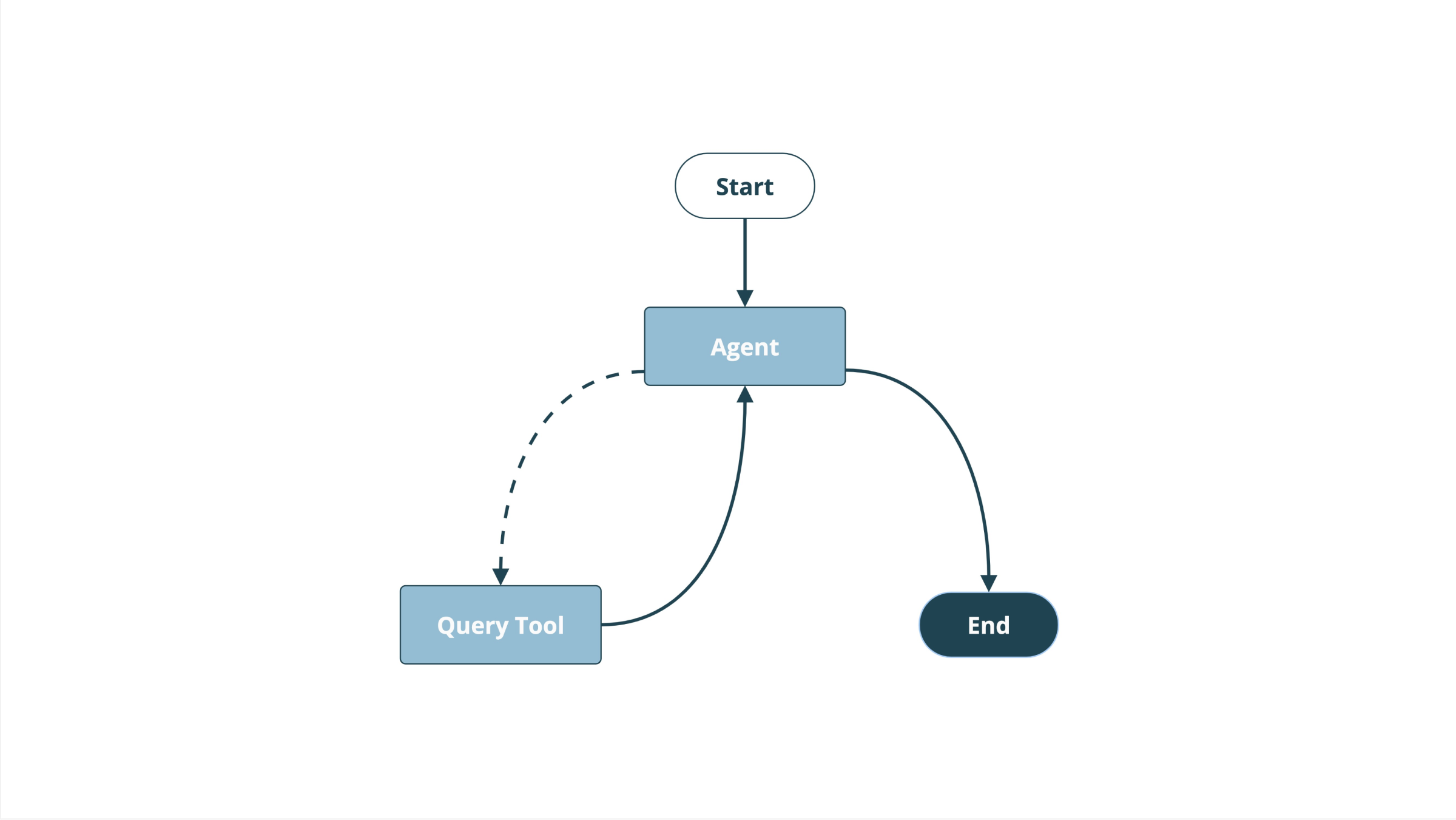
You may wonder why one wouldn't skip the tool step altogether and just let the agent formulate the SPARQL query. GPT-4o mini is certainly game to try. I quickly found, however, that even though the language model's queries were formally "correct," they usually failed to produce any results (let alone useful ones) in the face of Wikidata's real-world complexity. They also never came close to producing a result that inferred new information.
Separating the SPARQL query from the language model and providing clearly defined modular parameters represents a first step of deskilling the model through the composition of discrete tasks. LangGraph also provides visibility into the inputs and outputs of each node in the graph, which is crucial to iterating the model purposefully.
When executed against the test questions, this model worked reasonably well. It was able to answer most questions accurately based on the returned Wikidata facts, and was able to accurately incorporate its own general "knowledge" of the world to answer questions indirectly contained in the dataset (this is the case the question about the "oldest medalist from Africa" is designed to test).
When inspecting the model's performance, however, I found these correct responses were often the result of multiple tool calls and GPT-4o mini's ability to deal with large context inputs, which helped it find answers amid a messy (and often unrelated) set of source facts. When I limited the number of times the model could re-invoke the tool, its accuracy rate dropped significantly—from almost 100% to being right only half of the time.
Agent Zero
To further explore the degree to which this structural configuration was dependent on the language model, I swapped out the hosted model, GPT-4o mini, with an agent that could run locally on my MacBook Pro: Llama 3.1-8b.
📘 Agent Zero Notebook (GitHub)
As you might expect, the results were abysmal. To my surprise, it did respond correctly almost half of the time, but its incorrect responses were sophomorically verbose: it tended to just spit out whatever response it got from the tool and call it good.
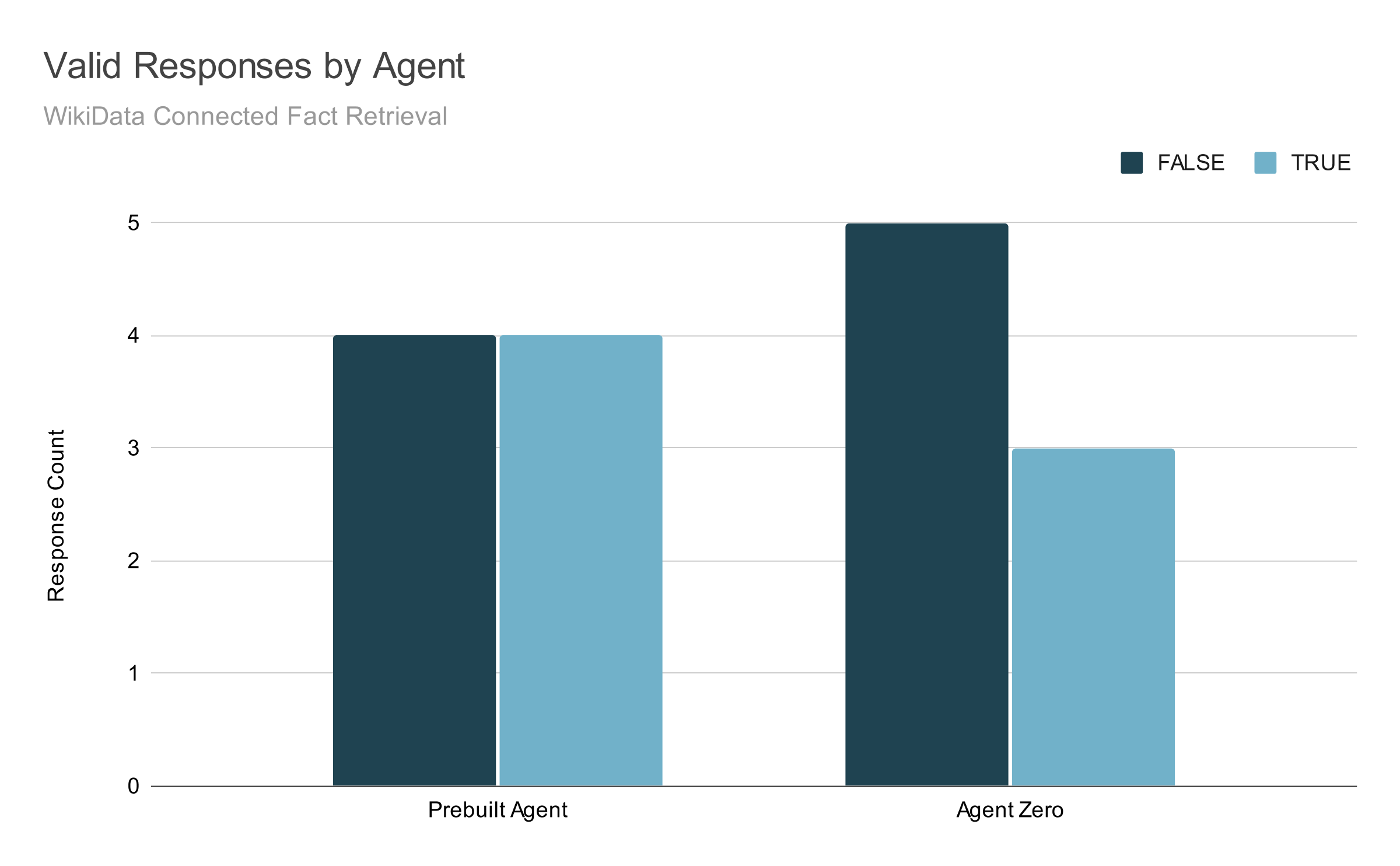
In effect, Agent Zero represents a half-completed job of deskilling: I had swapped out the labor, but did nothing to improve the technology.
No profits to pocket for me.
Second Test: Agent One
Given the high volume word salad Agent Zero favored for responses, I theorized that one key problem was the amount of information returned from the Wikidata SPARQL endpoint. Both the Prebuilt Agent and Agent Zero returned very large result sets. If I presented Llama 3.1 with a smaller set of facts, perhaps it would more consistently be able to process them.
📘 Agent One Notebook (GitHub)
For Agent One, then, I broke the decisions of what to ask and how to ask it into two separate steps by creating a "routing agent" responsible for deciding what the question was about, and set of "facet agents" designed to formulate a specific subset of query parameters (based on their designated facet). Each facet agent calls the query tool, passing in only the parameters that concern it. The query result is subsequently passed to a "response agent" that evaluates the question in light of the facts provided and formulates a response for the user.
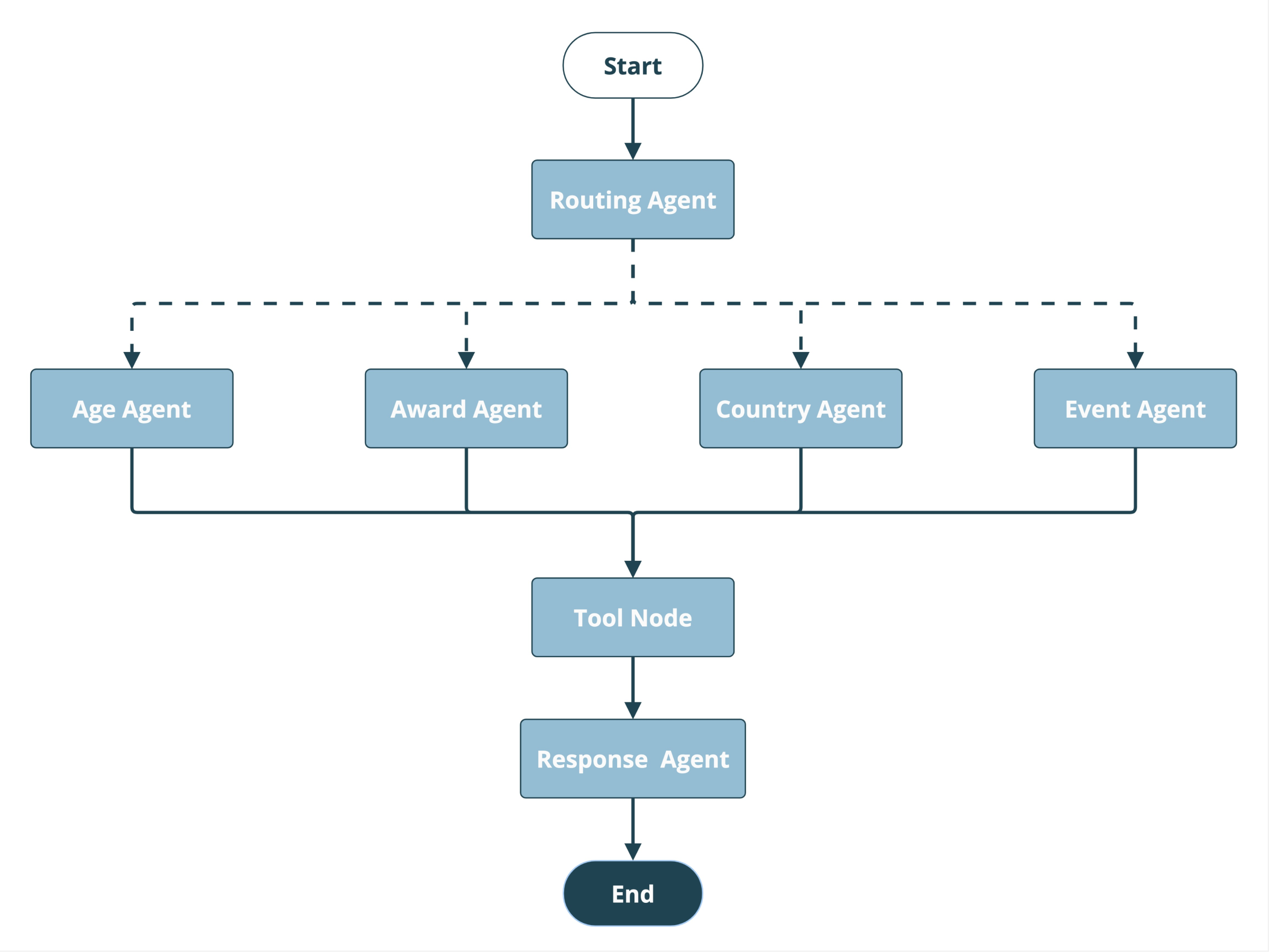
This agent builds on the DAG I had established in the Prebuilt Agent and adds in a separation of concerns which, theoretically, creates a greater degree of granularity for each agent. The prompts for each type of agent, and for each facet agent, define a smaller purview for each, ascribing a narrower range of action. The agents are then coordinated to eliminate the need for redundant tool node instances.
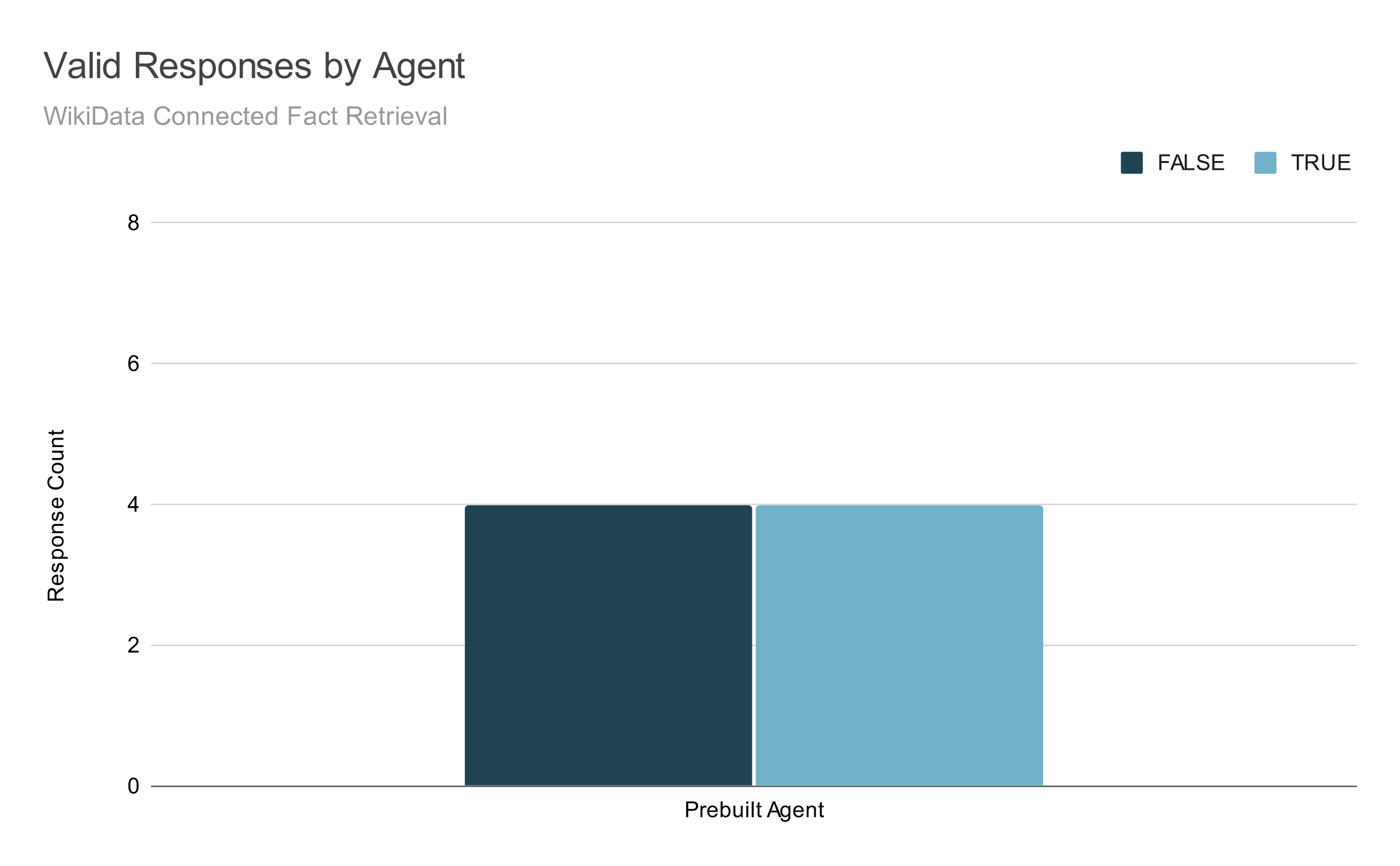
At first glance, Agent One’s performance on test questions seemed to be an improvement. The number of consistently "right" answers in the test set doubled compared to Agent Zero.
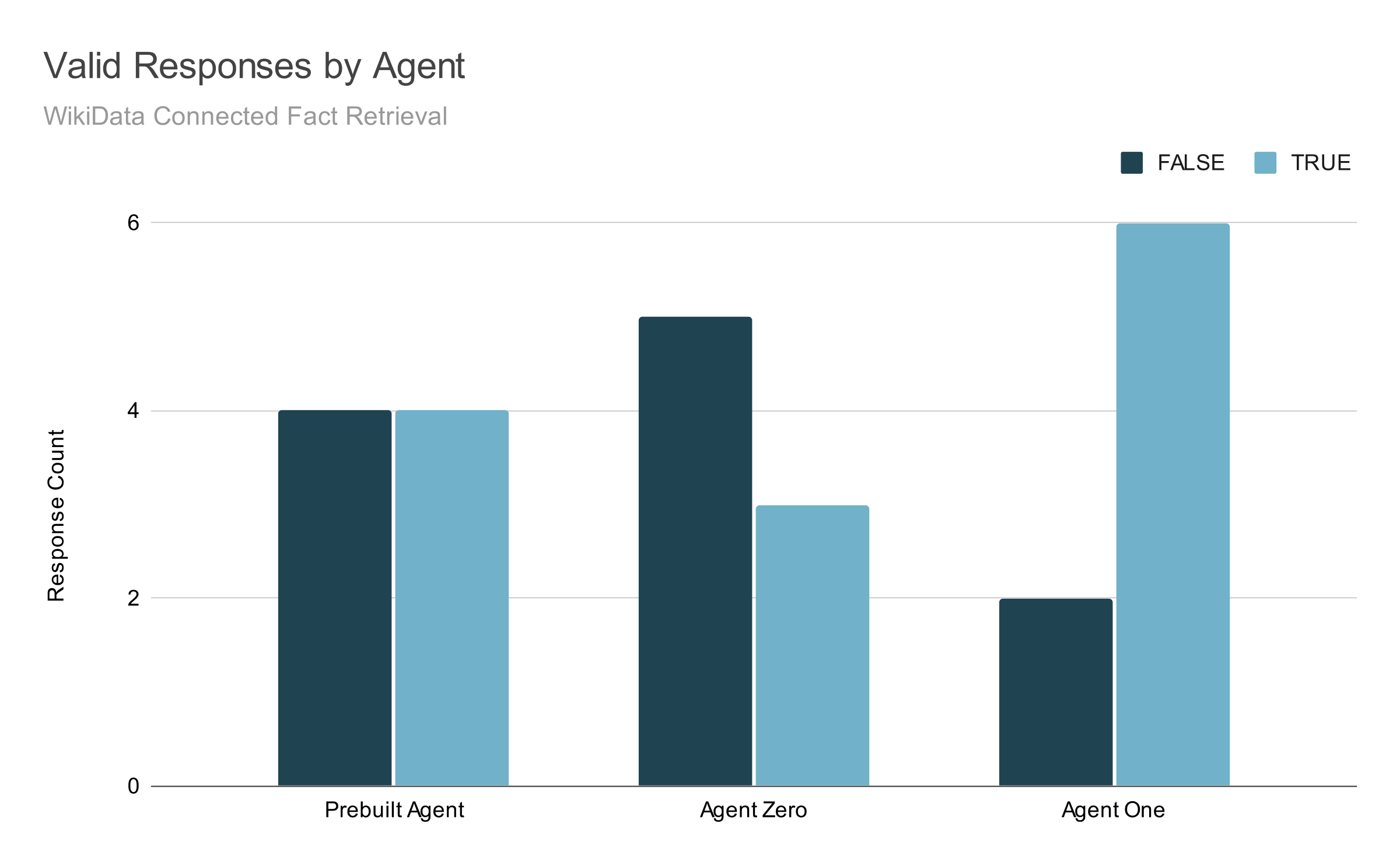
The answers that were wrong, however, were wrong in suspiciously inconsistent ways. Sometimes the right data was returned, but not interpreted correctly. Sometimes different questions were wrong for different reasons across multiple tests under the same conditions.
LangGraph uses a shared "scratchpad" of data called “state” to communicate between nodes. This offers a degree of visibility not possible with language models alone. By inspecting Agent One’s state, I was able to see exactly what messages, parameters, and prompts were passed between each node. What I discovered was that though Agent One returned correct answers most of the time, the Routing Agent was not very consistent at directing questions to the right facet agent, and the facet agents completely ignored the parameter constraints described in their system prompts.
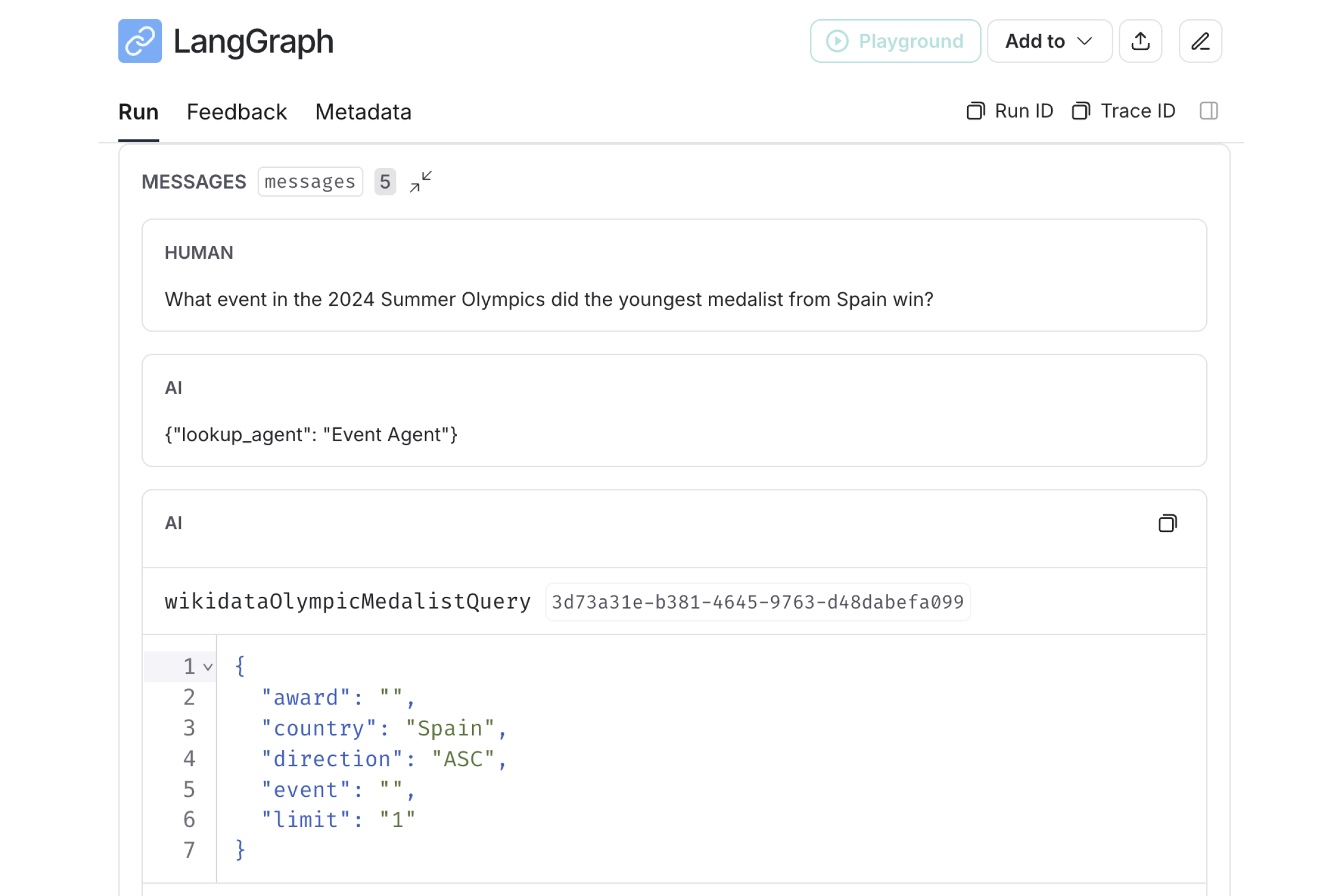
In the above image, for instance, we can see that the Routing Agent sent this question to the wrong facet agent: the "event" in question is what we need to know, not an available value for a parameter. We can also see that the Event Agent ignored its instruction to always return an "event" parameter.
Agent One ultimately got the answer right, but not in a way that would allow it to scale to answering more complex queries consistently. The visibility of these interactions helped me troubleshoot the agent and recognize that this approach was still not sufficiently granular to behave predictably.
Third Test: Agent Two
Agent One demonstrated that asking the LLM to choose which query parameters to set was still too complex of a task for Llama 3.1. In fact, allowing the configuration of multiple parameters was even problematic for GPT-4o mini: I suspect GPT-4o mini was only able to manage verbose Wikidata returns because it handled its context window better.
📘 Agent Two Notebook (GitHub)
The structure of Agent Two simplifies these decisions by eliminating them: instead of facet agents that handle clusters of related parameters, Agent Two uses one agent for each parameter. Those agents' only responsibility: determine the value for their assigned parameter.
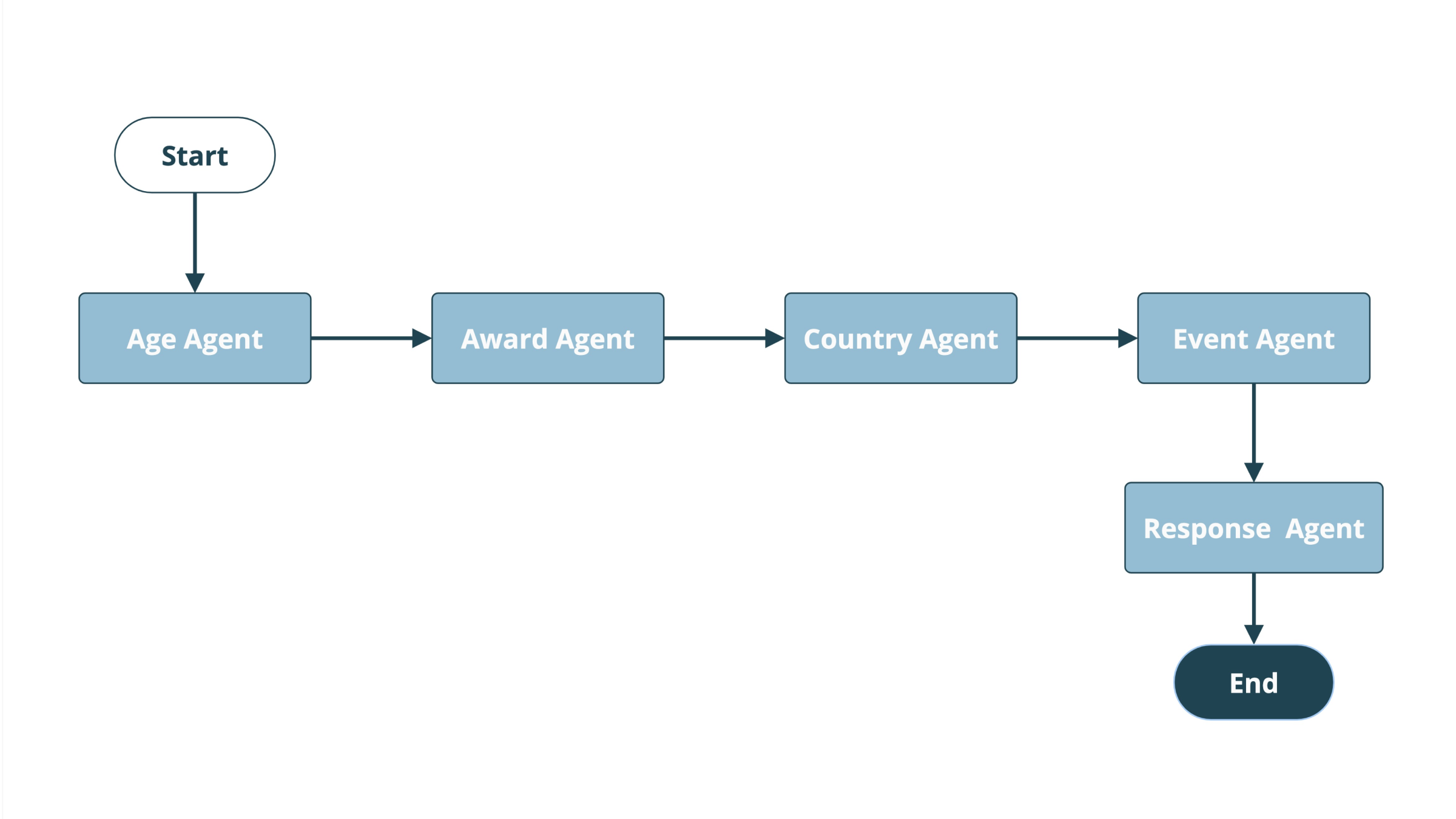
This structure means that each parameter is evaluated for every question, and that each model only needs to return one of two things: an appropriate value based on the question, or "None" to indicate that no value is needed.
Each parameter is joined to the preceding parameter and the final query is delivered to a simple function (a "runnable lambda") to retrieve the relevant Wikidata facts. These facts are then passed to a final response agent with strict instructions to answer the original question based only on the facts provided.
Since model-based decisions have been eliminated in this example, a simpler linear "chain" of agents replaces the DAG. Individual parameter agents are also considerably simpler in structure than their Facet Agent counterparts, which means the code to create them is more streamlined and simpler to iterate.
In terms of final response accuracy, Agent Two generated the same number of correct responses as Agent One:
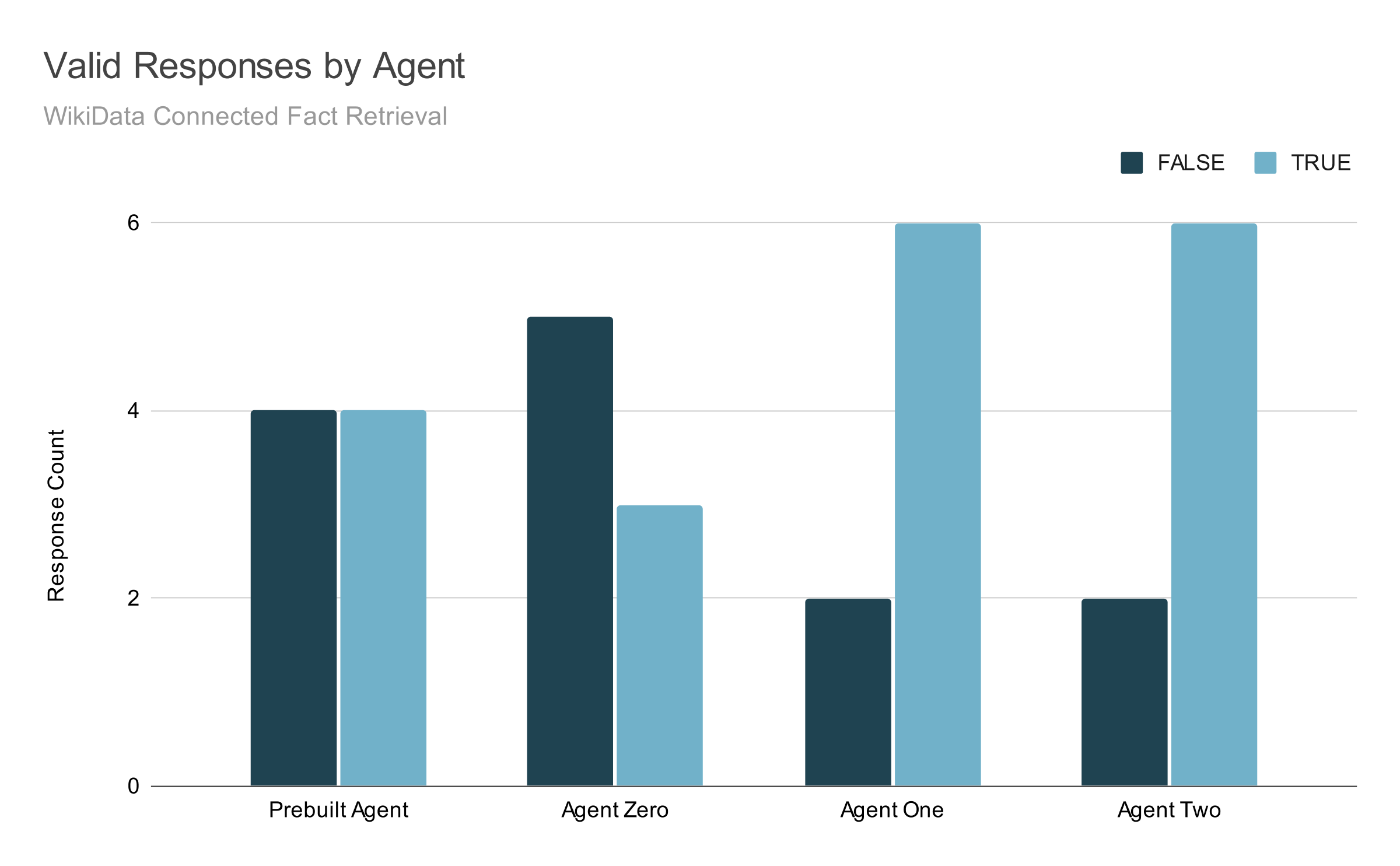
Agent Two still consistently misses two questions. There is a key difference, however: Agent Two always misses the same two questions, and it misses them not because it has returned the wrong facts (or too many facts) from Wikidata, but rather because the final response model consistently misinterprets facts about Spanish athletes' ages.
By examining the model trace in LangSmith, we can see that the query parameters created by Agent Two are accurate for the question asked:
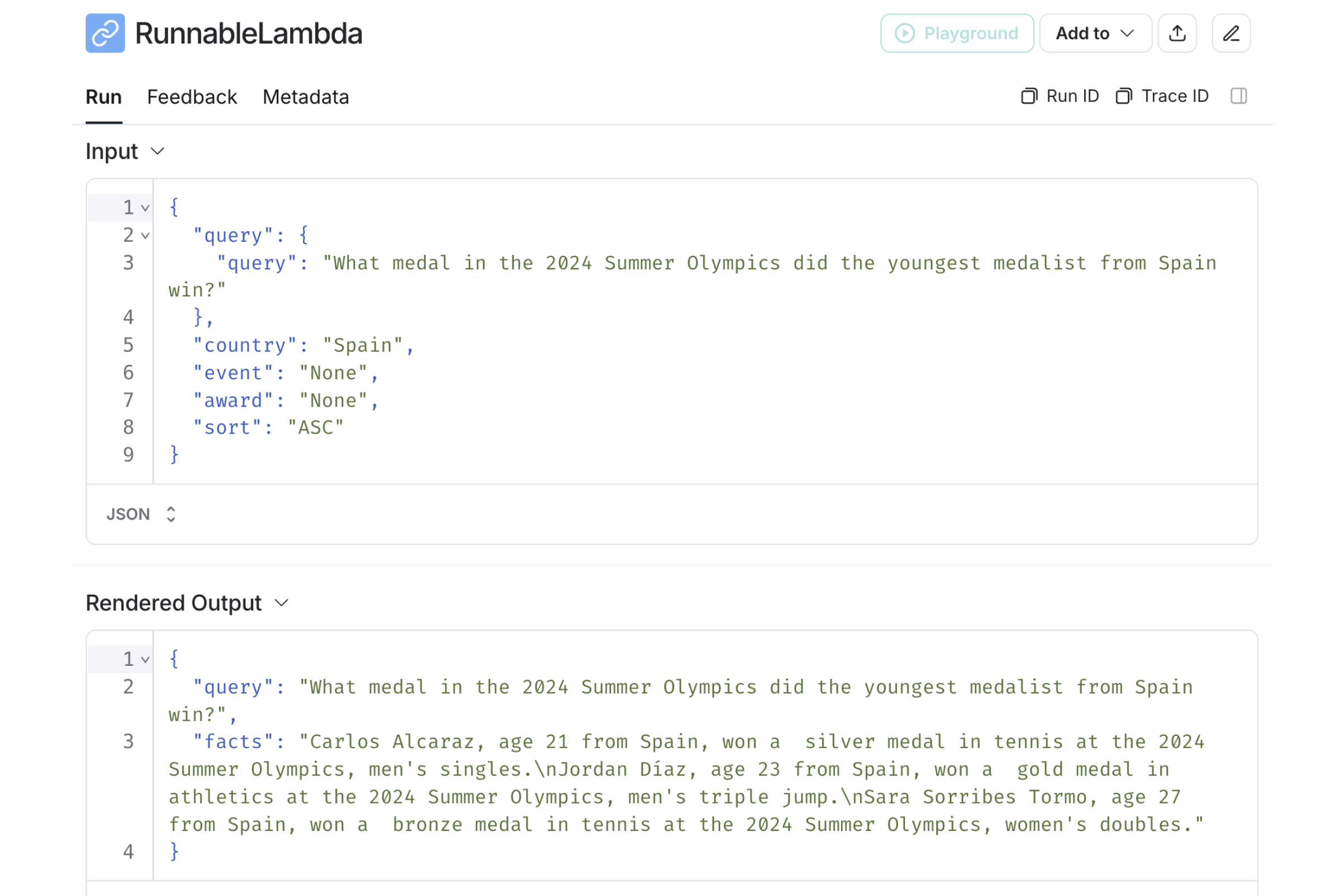
It’s when Llama 3.1 is asked to interpret that data, however, that things go sideways:

This is still, obviously, a problem that needs to be addressed. But it is a different problem than the one I set out to address in this experiment: how to dynamically generate a focused set of facts to ground an LLM's natural language response. That problem was resolved by composing tasks at the appropriate degree of granularity and iterating candidate structures by adjusting visible interactions and touchpoints to arrive at an effective solution.
Deskilling Takeaways
There is a lot of content out there right now about language model tools, technologies, and patterns. I haven't gone into the specifics of prompt composition, LangChain/LangGraph/LangSmith, or running models locally because there are already scores of excellent tutorials out there to get you started.
In addition to the technical implementation of model composition, however, there is also a set of problem solving and design considerations that need to be taken into account when using language models for practical work. "Deskilling" is one way to think through those considerations, and the manipulation and iteration of task composition, granularity, and visibility offer three facets by which it might be accomplished.
As the examples above demonstrate, deskilling is a continuum. Some tasks can be abstracted to structural tools (and a less "capable" LLM); others will require a more advanced model or human supervision—or both. In either case, the work of designing effectively orchestrated models is not engineering work alone: we must also understand and be able to articulate the goals, outputs, interactions, and points of failure of a model. These insights help us align the messy, imprecise realm of natural language with the deterministic realm of machine-readable facts and executable functions.
Deskilling also offers a path to understanding when an LLM is simply the wrong solution. In the final example above, where the Response Agent receives the right facts but fails to interpret them correctly, we could consider using a more advanced model to remedy the problem. Alternatively, we could also just deliver the returned facts as a response. Is there really more value to having a language model rephrase a concise set of clearly worded statements? The answer will depend on the use case, but it’s worth considering that using a language model here just because we've used them already may deliver a poorer experience at greater cost.
The rate at which language models and language model tooling have evolved over the last couple of years is truly stunning. I see every reason to believe they will continue to afford new ways to create useful, usable ways to find, understand, create, and share knowledge. While guidance for how to use language models judiciously and responsibly has not emerged with the same velocity as the tools themselves, my hope is that "deskilling" offers a point of view that helps you employ language models—or not—in a conscientious, purposeful way.