
Conversations with Robots: Voice, Smart Agents & the Case for Structured Content
This article first appeared on A List Apart. It is reprinted with permission.
In late 2016, Gartner predicted that 30 percent of web browsing sessions would be done without a screen by 2020. Earlier the same year, Comscore had predicted that half of all searches would be voice searches by 2020. Though there’s recent evidence to suggest that the 2020 picture may be more complicated than these broad-strokes projections imply, we’re already seeing the impact that voice search, artificial intelligence, and smart software agents like Alexa and Google Assistant are making on the way information is found and consumed on the web.
In addition to the indexing function that traditional search engines perform, smart agents and AI-powered search algorithms are now bringing into the mainstream two additional modes of accessing information: aggregation and inference. As a result, design efforts that focus on creating visually effective pages are no longer sufficient to ensure the integrity or accuracy of content published on the web. Rather, by focusing on providing access to information in a structured, systematic way that is legible to both humans and machines, content publishers can ensure that their content is both accessible and accurate in these new contexts, whether or not they’re producing chatbots or tapping into AI directly. In this article, we’ll look at the forms and impact of structured content, and we’ll close with a set of resources that can help you get started with a structured content approach to information design.
The Role of Structured Content
In their recent book, Designing Connected Content, Carrie Hane and Mike Atherton define structured content as content that is “planned, developed, and connected outside an interface so that it’s ready for any interface.” A structured content design approach frames content resources—like articles, recipes, product descriptions, how-tos, profiles, etc.—not as pages to be found and read, but as packages composed of small chunks of content data that all relate to one another in meaningful ways.
In a structured content design process, the relationships between content chunks are explicitly defined and described. This makes both the content chunks and the relationships between them legible to algorithms. Algorithms can then interpret a content package as the “page” I’m looking for—or remix and adapt that same content to give me a list of instructions, the number of stars on a review, the amount of time left until an office closes, and any number of other concise answers to specific questions.
Structured content is already a mainstay of many types of information on the web. Recipe listings, for instance, have been based on structured content for years. When I search, for example, “bouillabaisse recipe” on Google, I’m provided with a standard list of links to recipes, as well as an overview of recipe steps, an image, and a set of tags describing one example recipe:
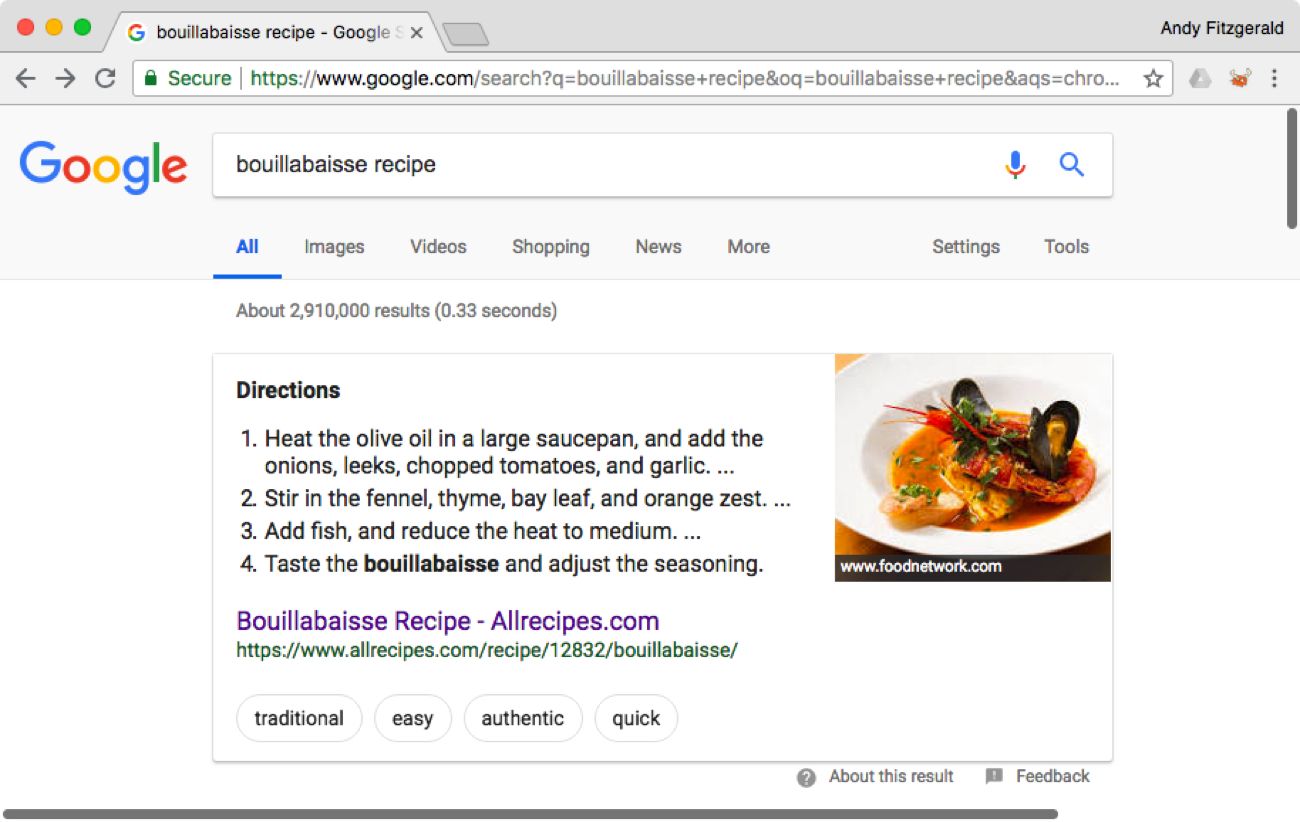
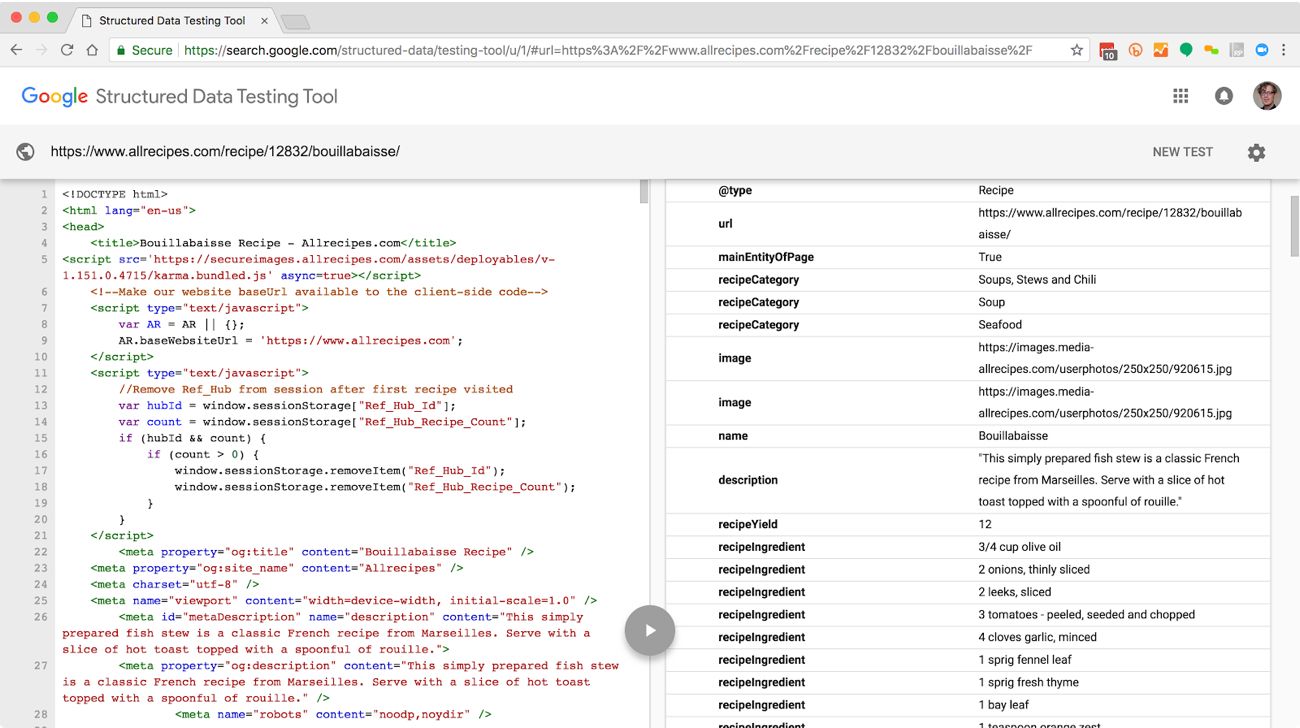
This “featured snippet” view is possible because the content publisher, allrecipes.com, has broken this recipe into the smallest meaningful chunks appropriate for this subject matter and audience, and then expressed information about those chunks and the relationships between them in a machine-readable way. In this example, allrecipes.com has used both semantic HTML and linked data to make this content not merely a page, but also legible, accessible data that can be accurately interpreted, adapted, and remixed by algorithms and smart agents. Let’s look at each of these elements in turn to see how they work together across indexing, aggregation, and inference contexts.
Software Agent Search and Semantic HTML
Semantic HTML is markup that communicates information about the meaningful relationships between document elements, as opposed to simply describing how they should look on screen. Semantic elements such as heading tags and list tags, for instance, indicate that the text they enclose is a heading <h1> for the set of list items <li> in the ordered list <ol> that follows.
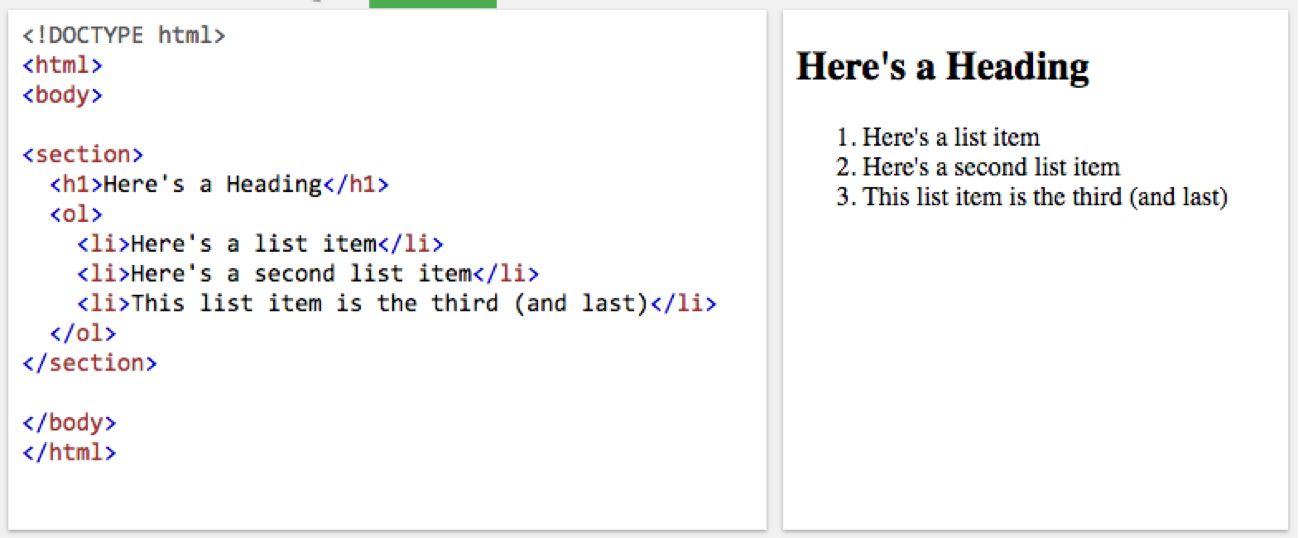
HTML structured in this way is both presentational and semantic because people know what headings and lists look like and mean, and algorithms can recognize them as elements with defined, interpretable relationships.
HTML markup that focuses only on the presentational aspects of a “page” may look perfectly fine to a human reader but be completely illegible to an algorithm. Take, for example, the City of Boston website, redesigned a few years ago in collaboration with top-tier design and development partners. If I want to find information about how to pay a parking ticket, a link from the home page takes me directly to the “How to Pay a Parking Ticket” screen (scrolled to show detail):
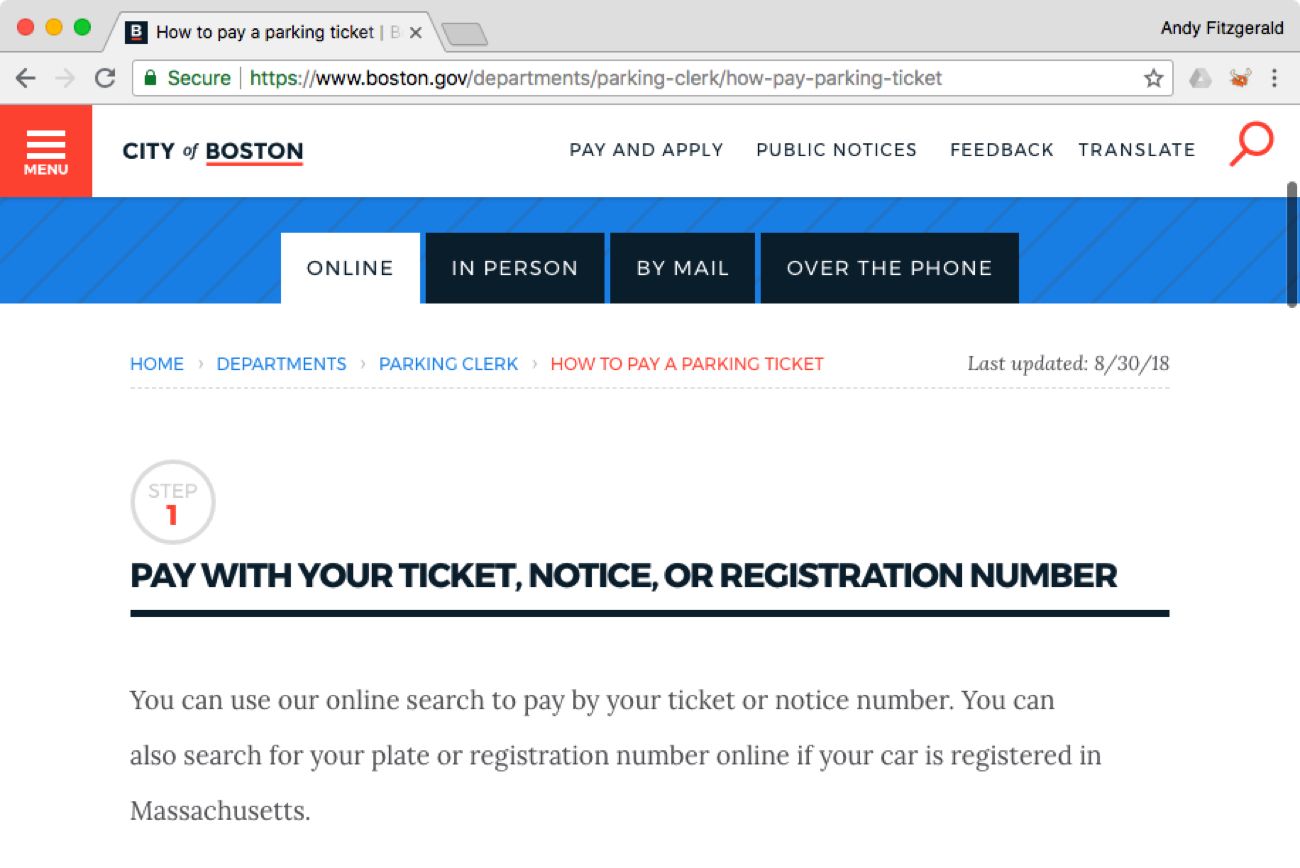
As a human reading this page, I easily understand what my options are for paying: I can pay online, in person, by mail, or over the phone. If I ask Google Assistant how to pay a parking ticket in Boston, however, things get a bit confusing:
None of the links provided in the Google Assistant results take me directly to the “How to Pay a Parking Ticket” page, nor do the descriptions clearly let me know I’m on the right track. (I didn’t ask about requesting a hearing.) This is because the content on the City of Boston parking ticket page is styled to communicate content relationships visually to human readers but is not structured semantically in a way that also communicates those relationships to inquisitive algorithms.
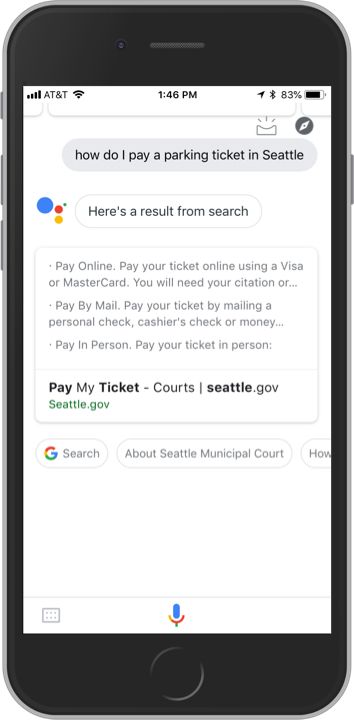
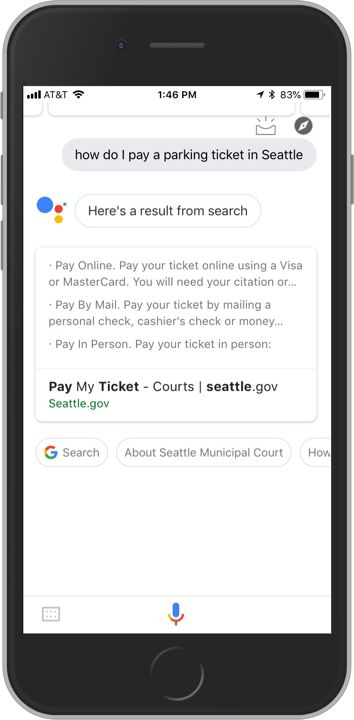
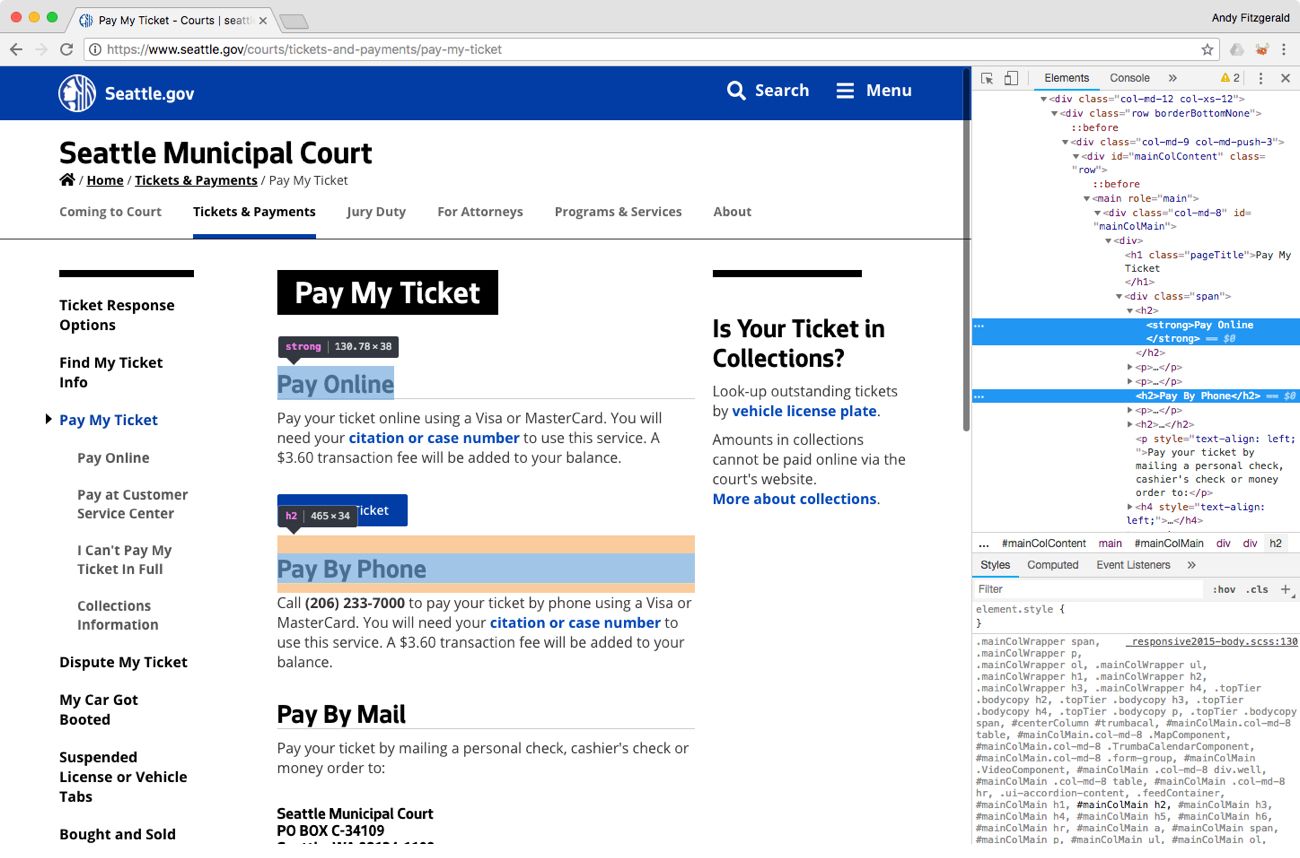
The City of Seattle’s “Pay My Ticket” page, though it lacks the polished visual style of Boston’s site, also communicates parking ticket payment options clearly to human visitors:
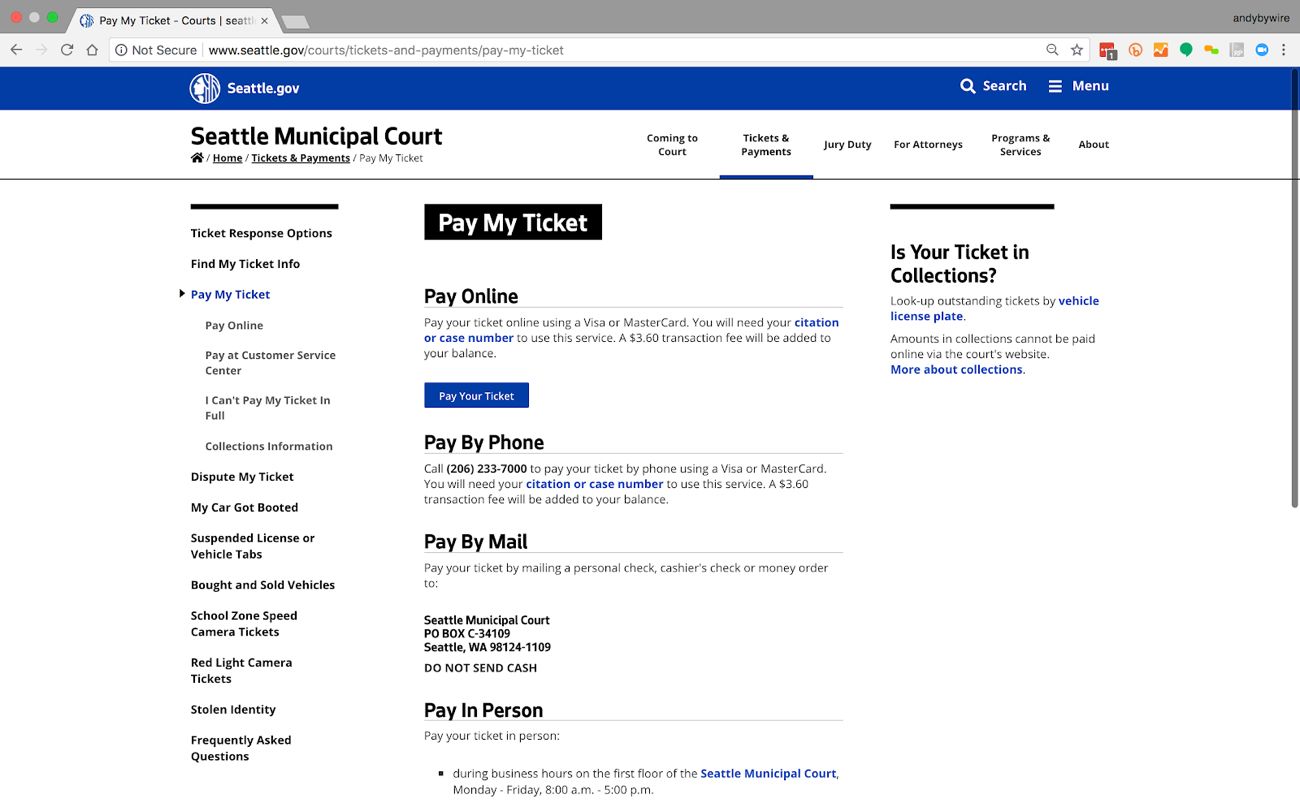
The equivalent Google Assistant search, however, offers a much more helpful result than we see with Boston. In this case, the Google Assistant result links directly to the “Pay My Ticket” page and also lists several ways I can pay my ticket: online, by mail, and in person.
Despite the visual simplicity of the City of Seattle parking ticket page, it more effectively ensures the integrity of its content across contexts because it’s composed of structured content that is marked up semantically. “Pay My Ticket” is a level-one heading <h1>, and each of the options below it are level-two headings <h2>, which indicate that they are subordinate to the level-one element.
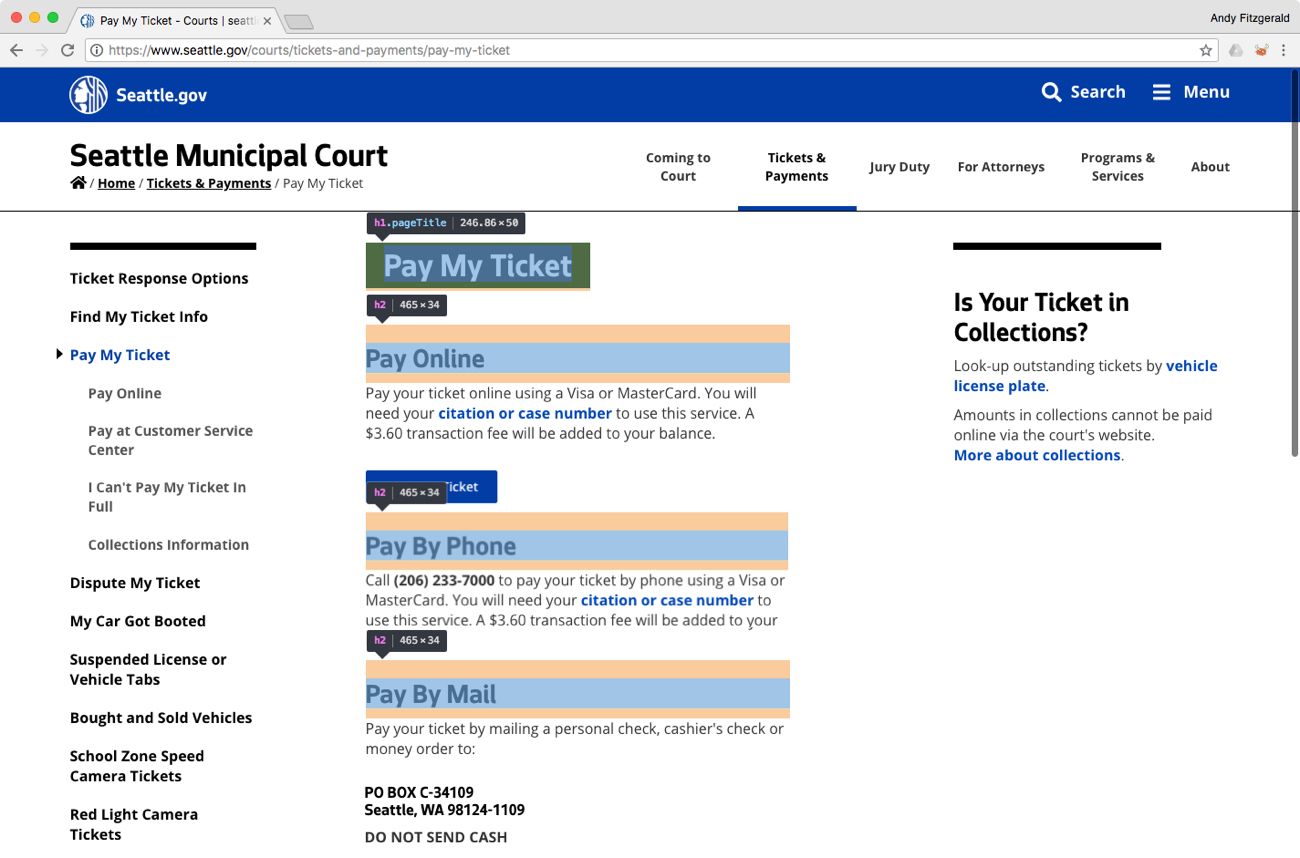
These elements, when designed well, communicate information hierarchy and relationships visually to readers, and semantically to algorithms. This structure allows Google Assistant to reasonably surmise that the text in these <h2> headings represents payment options under the <h1> heading “Pay My Ticket.”
While this use of semantic HTML offers distinct advantages over the “page display” styling we saw on the City of Boston’s site, the Seattle page also shows a weakness that is typical of manual approaches to semantic HTML. You’ll notice that, in the Google Assistant results, the “Pay by Phone” option we saw on the web page was not listed. If we look at the markup of this page, we can see that while the three options found by Google Assistant are wrapped in both <strong> and <h2> tags, “Pay by Phone” is only marked up with an <h2>. This irregularity in semantic structure may be what’s causing Google Assistant to omit this option from its results.
Although each of these elements would look the same to a sighted human creating this page, the machine interpreting it reads a difference. While WYSIWYG text entry fields can theoretically support semantic HTML, in practice they all too often fall prey to the idiosyncrasies of even the most well-intentioned content authors. By making meaningful content structure a core element of a site’s content management system, organizations can create semantically correct HTML for every element, every time. This is also the foundation that makes it possible to capitalize on the rich relationship descriptions afforded by linked data.
Linked Data and Content Aggregation
In addition to finding and excerpting information, such as recipe steps or parking ticket payment options, search and software agent algorithms also now aggregate content from multiple sources by using linked data.
In its most basic form, linked data is “a set of best practices for connecting structured data on the web.” Linked data extends the basic capabilities of semantic HTML by describing not only what kind of thing a page element is (“Pay My Ticket” is an <h1>), but also the real-world concept that thing represents: this <h1> represents a “pay action,” which inherits the structural characteristics of “trade actions” (the exchange of goods and services for money) and “actions” (activities carried out by an agent upon an object). Linked data creates a richer, more nuanced description of the relationship between page elements, and it provides the structural and conceptual information that algorithms need to meaningfully bring data together from disparate sources.
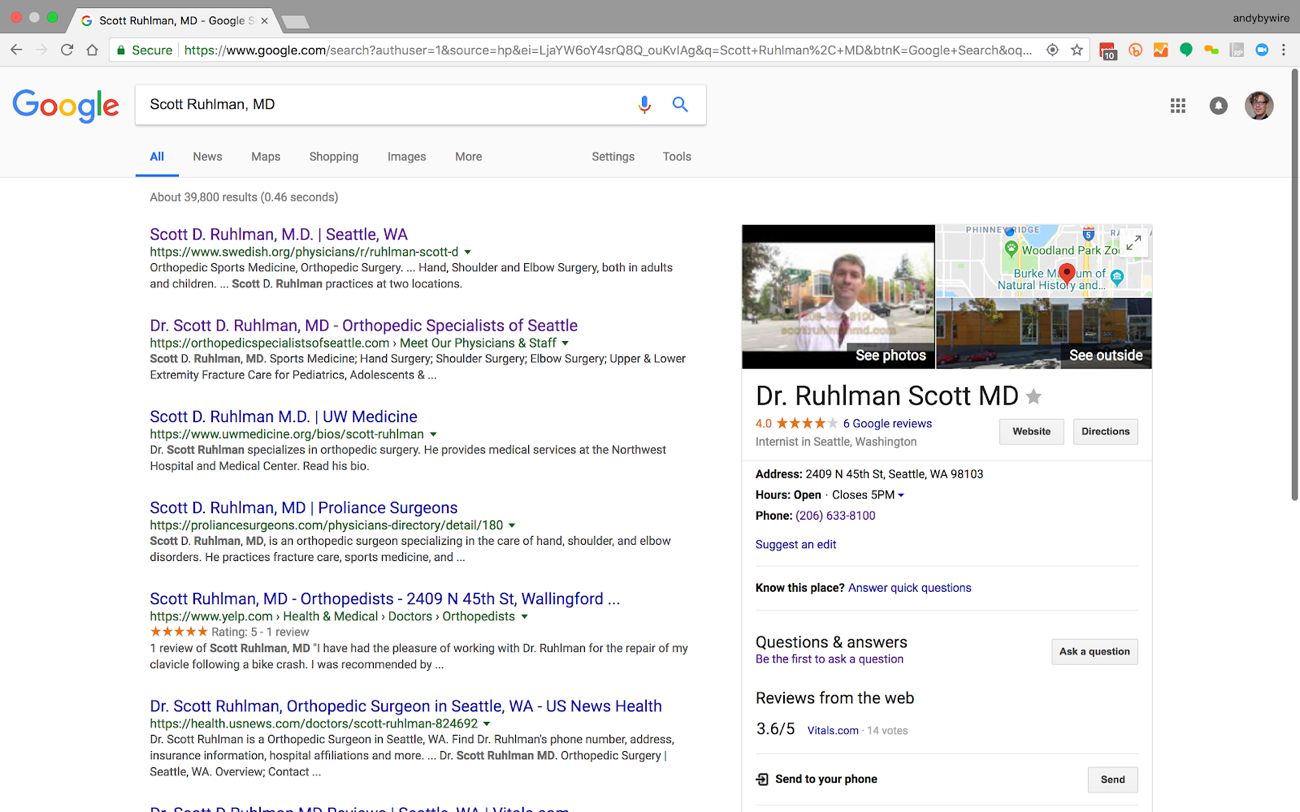
Say, for example, that I want to gather more information about two recommendations I’ve been given for orthopedic surgeons. A search for a first recommendation, Scott Ruhlman, MD, brings up a set of links as well as a Knowledge Graph info box containing a photo, location, hours, phone number, and reviews from the web.
If we run Dr. Ruhlman’s Swedish Hospital profile page through Google’s Structured Data Testing Tool, we can see that content about him is structured as small, discrete elements, each of which is marked up with descriptive types and attributes that communicate both the meaning of those attributes’ values and the way they fit together as a whole—all in a machine-readable format.
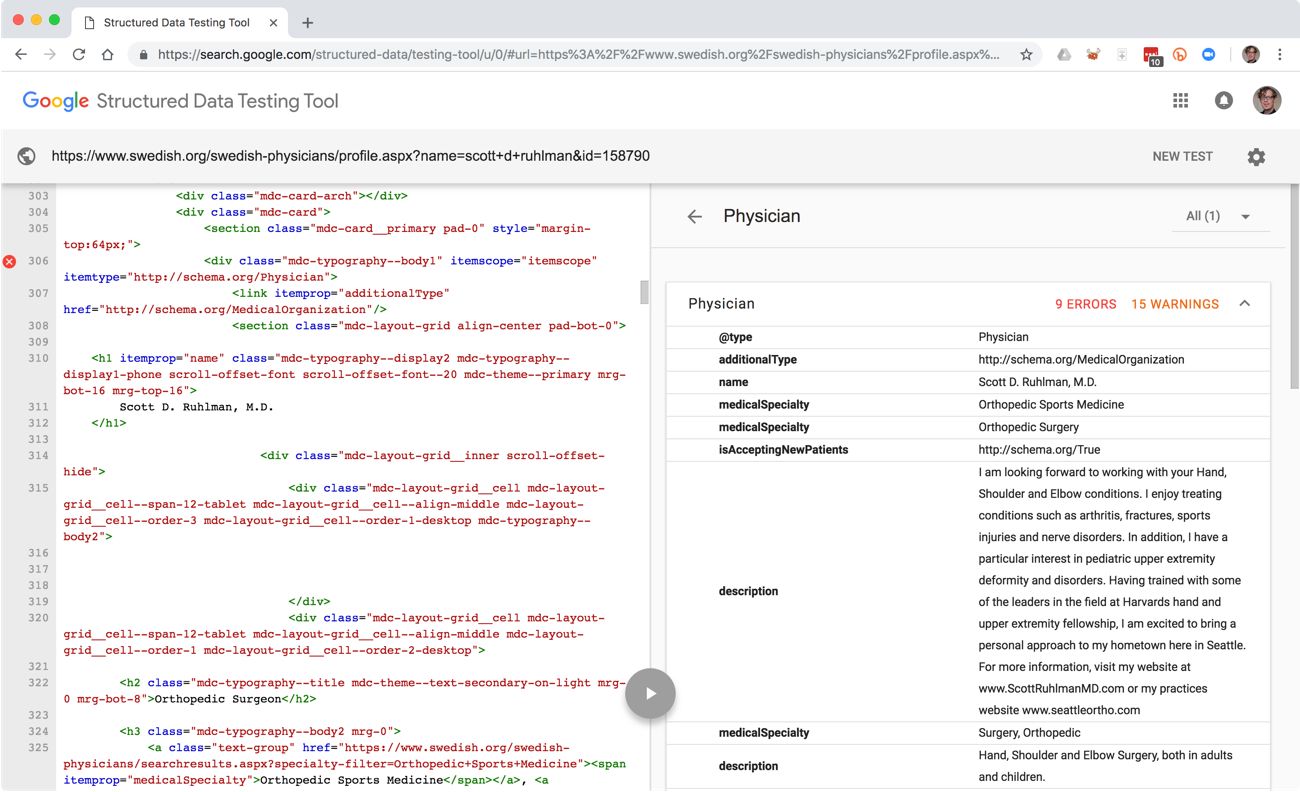
In this example, Dr. Ruhlman’s profile is marked up with microdata based on the schema.org vocabulary. Schema.org is a collaborative effort backed by Google, Yahoo, Bing, and Yandex that aims to create a common language for digital resources on the web. This structured content foundation provides the semantic base on which additional content relationships can be built. The Knowledge Graph info box, for instance, includes Google reviews, which are not part of Dr. Ruhlman’s profile, but which have been aggregated into this overview. The overview also includes an interactive map, made possible because Dr. Ruhlman’s office location is machine-readable.
The search for a second recommendation, Stacey Donion, MD, provides a very different experience. Like the City of Boston site above, Dr. Donion’s profile on the Kaiser Permanente website is perfectly intelligible to a sighted human reader. But because its markup is entirely presentational, its content is virtually invisible to software agents.
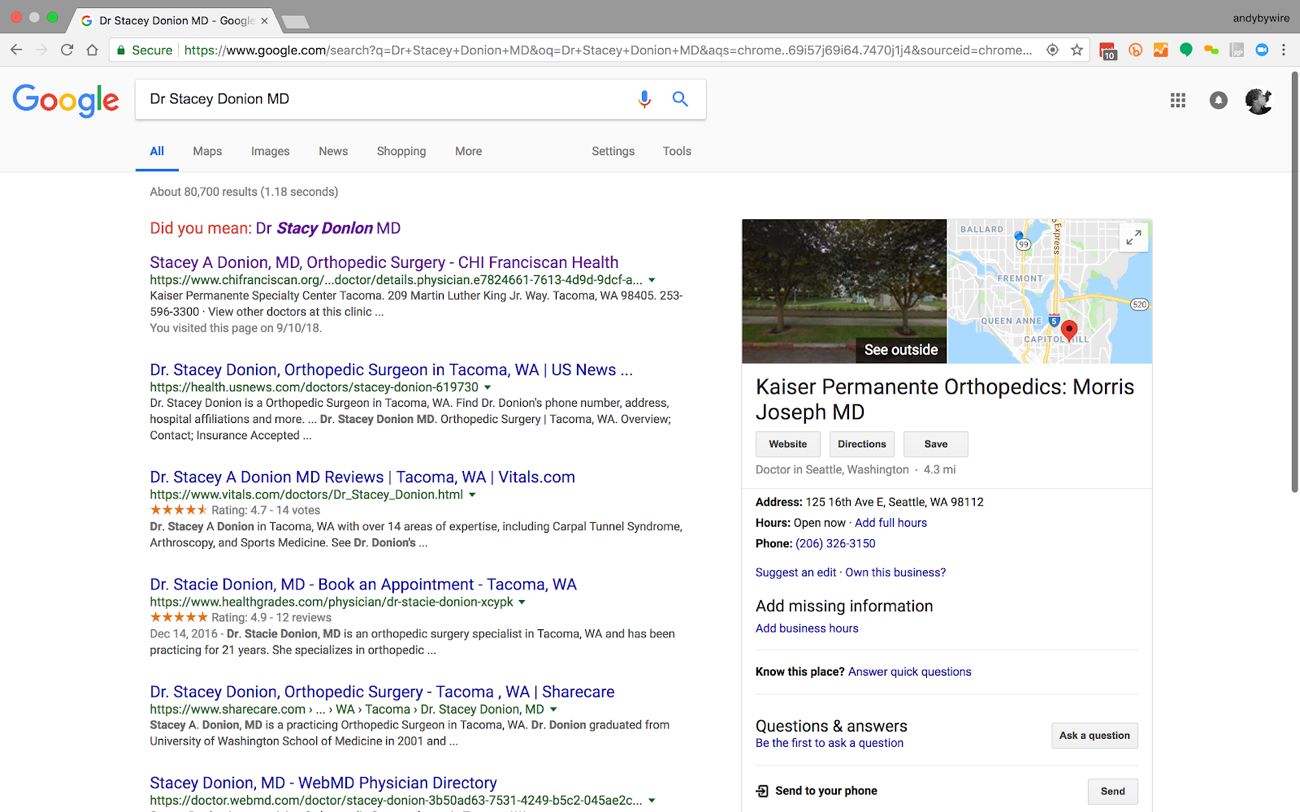
In this example, we can see that Google is able to find plenty of links to Dr. Donion in its standard index results, but it isn’t able to “understand” the information about those sources well enough to present an aggregated result. In this case, the Knowledge Graph knows Dr. Donion is a Kaiser Permanente physician, but it pulls in the wrong location and the wrong physician’s name in its attempt to build a Knowledge Graph display.
You’ll also notice that while Dr. Stacey Donion is an exact match in all of the listed search results—which are numerous enough to fill the first results page—we’re shown a “did you mean” link for a different doctor. Stacy Donlon, MD, is a neurologist who practices at MultiCare Neuroscience Center, which is not affiliated with Kaiser Permanente. Multicare does, however, provide semantic and linked data-rich profiles for their physicians.
Voice Queries and Content Inference
The increasing prevalence of voice as a mode of access to information makes providing structured, machine-intelligible content all the more important. Voice and smart software agents are not just freeing users from their keyboards, they’re changing user behavior. According to LSA Insider, there are several important differences between voice queries and typed queries. Voice queries tend to be:
- longer;
- more likely to ask who, what, and where;
- more conversational;
- and more specific.
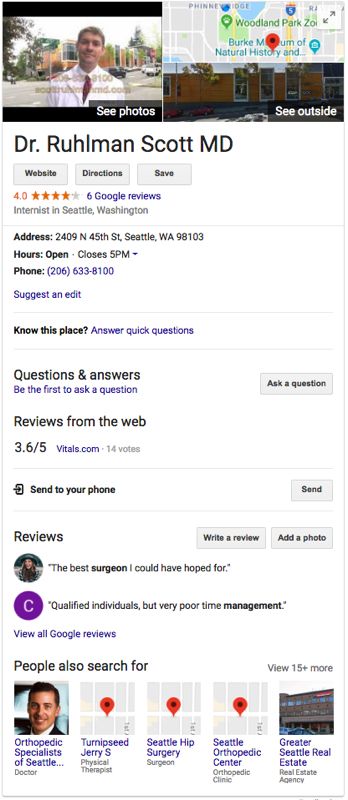
In order to tailor results to these more specifically formulated queries, software agents have begun inferring intent and then using the linked data at their disposal to assemble a targeted, concise response. If I ask Google Assistant what time Dr. Ruhlman’s office closes, for instance, it responds, “Dr. Ruhlman’s office closes at 5 p.m.,” and displays this result:
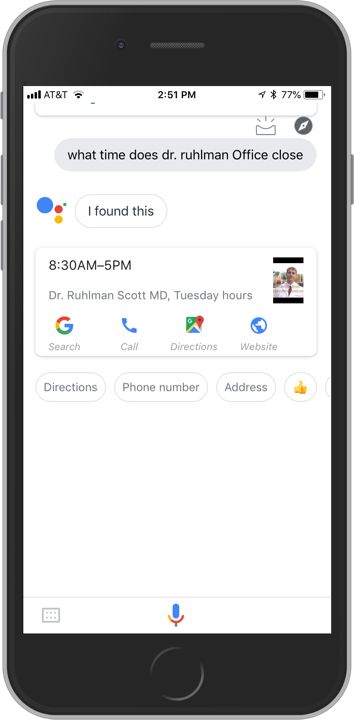
These results are not only aggregated from disparate sources, but are interpreted and remixed to provide a customized response to my specific question. Getting directions, placing a phone call, and accessing Dr. Ruhlman’s profile page on swedish.org are all at the tips of my fingers.
When I ask Google Assistant what time Dr. Donion’s office closes, the result is not only less helpful but actually points me in the wrong direction. Instead of a targeted selection of focused actions to follow up on my query, I’m presented with the hours of operation and contact information for MultiCare Neuroscience Center.
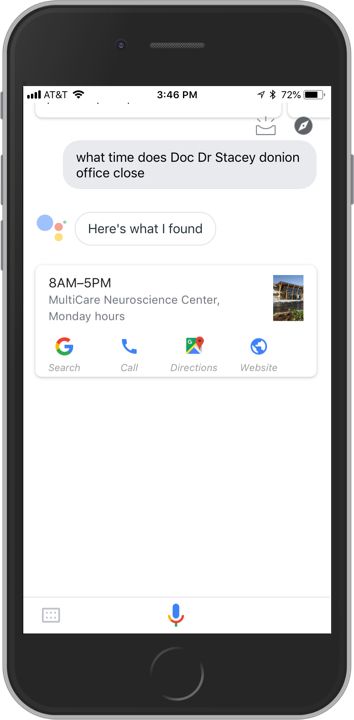
MultiCare Neuroscience Center, you’ll recall, is where Dr. Donlon—the neuroscientist Google thinks I may be looking for, not the orthopedic surgeon I’m actually looking for—practices. Dr. Donlon’s profile page, much like Dr. Ruhlman’s, is semantically structured and marked up with linked data.
To be fair, subsequent trials of this search did produce the generic (and partially incorrect) practice location for Dr. Donion (“Kaiser Permanente Orthopedics: Morris Joseph MD”). It is possible that through repeated exposure to the search term “Dr. Stacey Donion,” Google Assistant fine-tuned the responses it provided. The initial result, however, suggests that smart agents may be at least partially susceptible to the same availability heuristic that affects humans, wherein the information that is easiest to recall often seems the most correct.
There’s not enough evidence in this small sample to support a broad claim that algorithms have “cognitive” bias, but even when we allow for potentially confounding variables, we can see the compounding problems we risk by ignoring structured content. “Donlon,” for example, may well be a more common name than “Donion” and may be easily mistyped on a QWERTY keyboard. Regardless, the Kaiser Permanente result we’re given above for Dr. Donion is for the wrong physician. Furthermore, in the Google Assistant voice search, the interaction format doesn’t verify whether we meant Dr. Donlon; it just provides us with her facility’s contact information. In these cases, providing clear, machine-readable content can only work to our advantage.
The Business Case for Structured Content Design
In 2012, content strategist Karen McGrane wrote that “you don’t get to decide which platform or device your customers use to access your content: they do.”
This statement was intended to help designers, strategists, and businesses prepare for the imminent rise of mobile. It continues to ring true for the era of linked data. With the growing prevalence of smart assistants and voice-based queries, an organization’s website is less and less likely to be a potential visitor’s first encounter with rich content. In many cases—such as finding location information, hours, phone numbers, and ratings—this pre-visit engagement may be a user’s only interaction with an information source.
These kinds of quick interactions, however, are only one small piece of a much larger issue: linked data is increasingly key to maintaining the integrity of content online. The organizations I’ve used as examples, like the hospitals, government agencies, and colleges I’ve consulted with for years, don’t measure the success of their communications efforts in page views or ad clicks. Success for them means connecting patients, constituents, and community members with services and accurate information about the organization, wherever that information might be found. This communication-based definition of success readily applies to virtually any type of organization working to further its business goals on the web.
The model of building pages and then expecting users to discover and parse those pages to answer questions, though time-tested in the pre-voice era, is quickly becoming insufficient for effective communication. It precludes organizations from participating in emergent patterns of information seeking and discovery. And—as we saw in the case of searching for information about physicians—it may lead software agents to make inferences based on insufficient or erroneous information, potentially routing customers to competitors who communicate more effectively.
By communicating clearly in a digital context that now includes aggregation and inference, organizations are more effectively able to speak to their users where users actually are, be it on a website, a search engine results page, or a voice-controlled digital assistant. They are also able to maintain greater control over the accuracy of their messages by ensuring that the correct content can be found and communicated across contexts.