
AI Supported Auto-Categorization
For the last few weeks, I've been exploring ways that AI and LLMs do—and don't—fit into taxonomy design and development for content-driven websites. I've written about:
- AI Supported Taxonomy Term Generation, for which I've found there are some compelling use cases for integrating LLMs
- Purpose-Driven Taxonomy Design, in which the primary challenge I see clients struggle with is defining what the taxonomy needs to accomplish (for which you'll need to—gasp!—actually talk to other humans)
- Migrating a Taxonomy to the CMS, which can be significantly streamlined when your work is based on established semantic web standards
Once your taxonomy is integrated into your CMS, the next step, naturally, is to tag your content. This is what allows you to put the domain knowledge represented by your taxonomy to use to recommend content, display collections, navigate, support search, inform analytics, surface content opportunities, etc.
If you already have a collection of several thousand accurately tagged articles and you need to tag more, using an enterprise taxonomy tool to train a machine learning model to tag new content may be a feasible way to get this done. If you're not in the fortunate position of having a critical mass of accurately tagged content, your options have traditionally been manually slogging through the content set with human taggers, or using deterministic natural language processing (NLP) algorithms and models to assign tags.
But we live in 2025! Surely LLMs can help with this. Right? If you've been on The Internet lately, you've certainly seen examples aplenty of LLMs creating reasonable-looking sets of tags for content, seemingly out of thin air. But are these tags effective? And are they any better than what a human tagger or NLP process would produce?
An Experiment
Since the content set I've been using as a running example in the last few articles is small enough for one person to tag manually, I took the opportunity to conduct an experiment. I ran human, NLP, and LLM tagging approaches on a sample set of articles to evaluate each approach for consistency.
My hypothesis, based similar experiences I've had with recent client work, was that the (deterministic) NLP approach would be at least as accurate as the LLM approach, and would, in the final implementation, involve less overhead that keeping an LLM from going off the rails.
It turns out that I was wrong.
But I was not wrong in the way I expected to be: A comparison of methods showed not the inherent differences of one algorithmic approach over the other—or even over manual human tagging. Rather, each approach produced a result that looked right ... but that may or may not be effective for achieving the user-centered goals intended.
In short, I was reminded that you can't do human-centered design without input from the humans for whom the design is intended. 🤷♂️
In the spirit of sharing this rediscovery of the obvious—and with the suspicion that it might be a useful reminder for others in these heady AI times—here's a look at:
- the small sample size experiment I ran with human, deterministic, and LLM-based auto-tagging
- the outcomes and the findings produced
- a perspective on managing and setting expectations for tagging projects in our nascent era of ubiquitous LLMs
Auto-Tagging Approaches
To establish a baseline for what an appropriate set of tags should include, I first manually tagged all the articles in the content collection in question with four terms each from the new taxonomy. This took roughly four hours (not counting breaks—of which I needed plenty).
I also enlisted two experienced information architecture colleagues to tag the three most difficult and the three easiest articles. They were given the same parameters I used to tag content myself: aim for four tags per article focused on the article's overall topic, its "aboutness," in light of the intended audience and use cases for the content and the site. (My colleagues were much faster than I was—it turns out I'm a lousy scanner).
Natural Language Processing Auto-Tagging
Natural Language Processing (NLP) uses linguistic models and rules-based interpretation methods to deterministically generate information about natural language texts. The NLP process I set up to tag the six sample articles used BERT sentence transformers to calculate semantic similarity between a given article and the definition of each taxonomy term at three levels:
- Document similarity compared the entire article to each taxonomy term definition
- Paragraph similarity compared each paragraph to taxonomy term definitions and selected the highest-scoring terms
- Sentence similarity compared each sentence to taxonomy term definitions and selected the highest-scoring terms
I then weighted these scores for each term, with the document score carrying the most weight (60%) and the maximum sentence score carrying the least (10%). This produced a final similarity score for each term definition, of which the top four were selected as tags. This process took 2.5 hours to set up and run.
👉 View the annotated NLP Auto-Tagging Jupyter Notebook
Large Language Model Auto-Tagging
Finally, I used OpenAI's GPT-4o-mini to tag articles via LLM. Since 4o's context window can handle 128,000 tokens, I was able to feed it an entire article and the entire taxonomy, including definitions, for each article to be tagged. I set the temperature of the model to zero to limit fanciful embellishment and loquacious asides.
As you would expect, it took some experimentation and iteration to get the prompt right, but I was eventually able to get the model to return a set of appropriate tag labels as a JSON file I could compare with the other results. This process took about two hours overall and incurred a total of $0.93 cents in API fees.
👉 View the annotated LLM Auto-Tagging Jupyter Notebook
Results
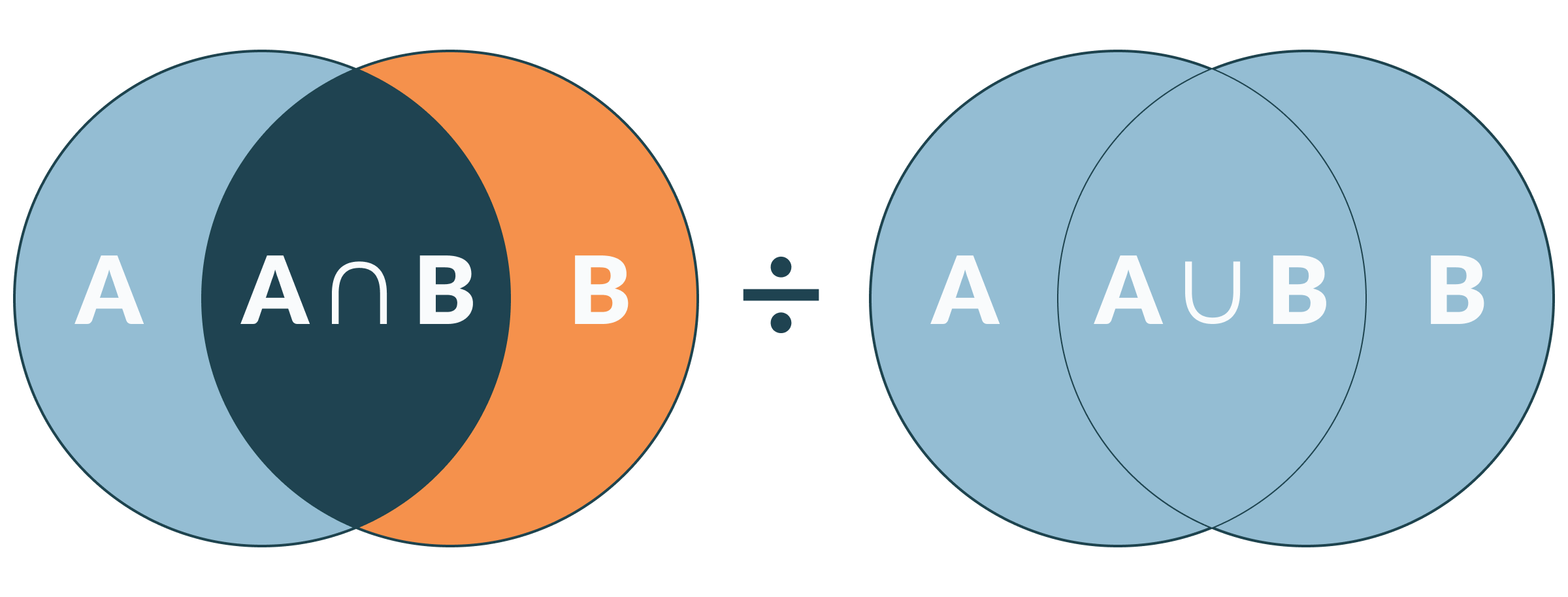
To assess the consistency of each approach, I calculated the Jaccard index across all possible combinations of tag results. For two sets of values, which in this case amounts to up to eight tags, the Jaccard index calculates the similarity and diversity between the sets by dividing the intersection of the sets (the count of which values they have in common) by the union of the sets (the total number of unique values between them).
The results, shown in the heat map below, indicate the average degree of agreement between individual tagging agents: three humans, one NLP process, and one LLM process. One is complete agreement. Zero means that the set of tags provide by each were completely different.
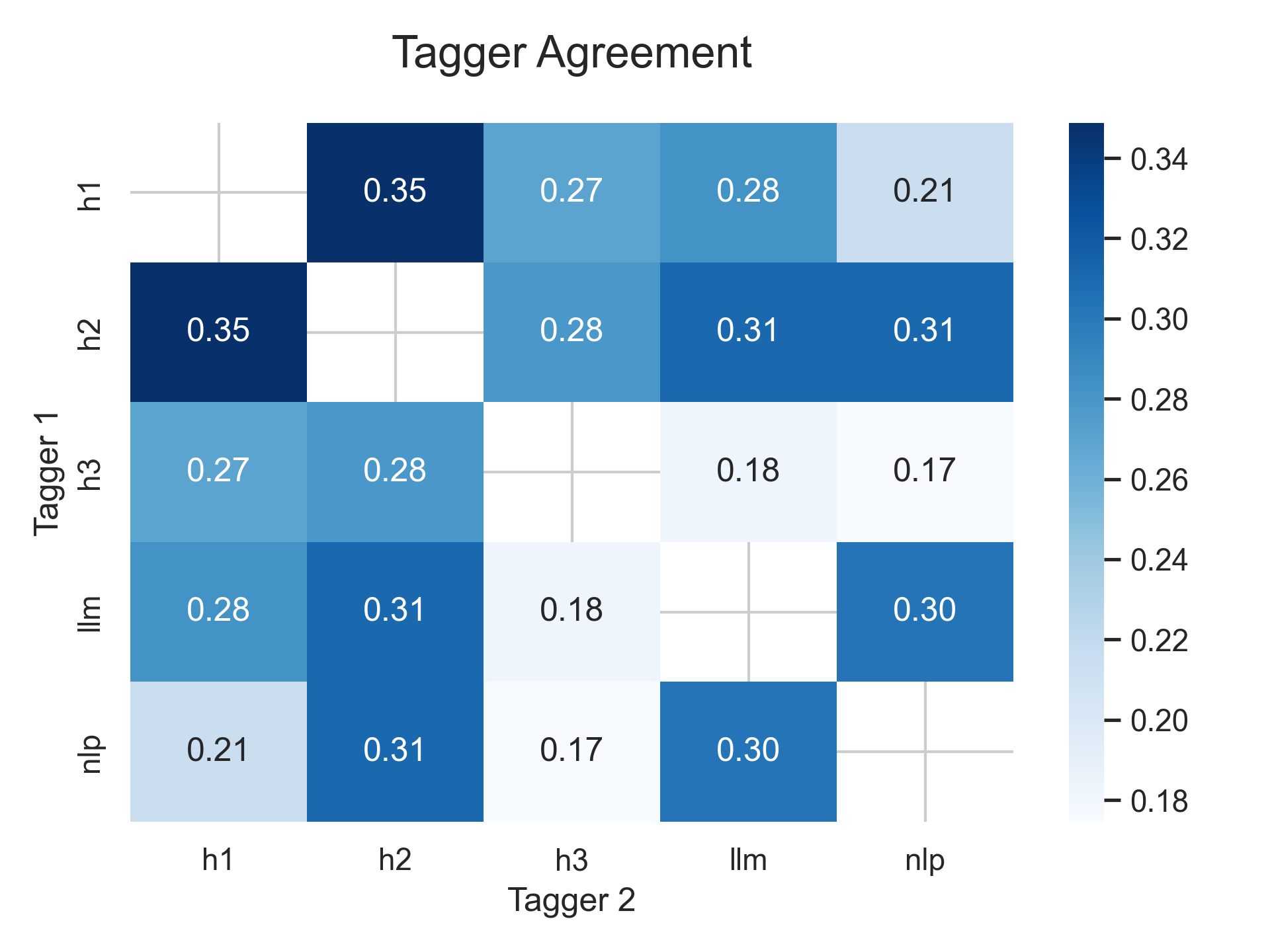
None of these are what I would consider strong results for any pair—including pairs of human taggers. Likewise, neither the NLP nor the LLM process represent a significant difference in the consistency offered by manual tagging.
So how do we know which set of tags is the most effective for the goals established for this content collection (and outlined in the Purpose Driven Taxonomy Design article)? We would need to know which approach is able, from the user's point of view, to:
- coordinate content recommendations
- communicate the range of topics covered
- afford topic-based browsing
Even if the three human taggers had stronger agreement on which tags to choose for each article, this still doesn't tell us that those tags will achieve these goals for users in the context in which they'll encounter them. To discover this answer, we need to engage not with some new tool or learning model, but rather with the actual users themselves.
As a fairly seasoned UX professional, this finding wasn't exactly a shocker. What did take me by surprise was how equally worthless each of the three techniques I tried above is in the absence of this user insight. With so much attention focused on what LLMs can do, it's somehow refreshing to be starkly reminded that human-centered design still requires human involvement in a fundamental way.
Takeaways
Fortunately, there are several common and well-established methods for collecting this missing insight.
Prior to Tagging
If it's important that your taxonomy and tagging strategy meet improvement goals at launch, you'll want to engage with users before you start tagging content, and ideally before you finalize your taxonomy. Two common and well-established methods for accomplishing this are:
- Tree testing, which uses a raw, text-based "tree" of topic tags to test out candidate structures with potential users
- Prototype usability testing, which presents potential users with a mocked-up version of a content collection (and its hierarchy) and leads them to complete a set of defined tasks with the proposed design
Both of these are effective, low-cost ways to vet a proposed topic hierarchy and tagging approach prior to implementation. They can also be effective ways to find out if your labels and categories deliver the "information scent" needed to guide users to related topics and content.
These techniques only work, of course, if you actually do them. Asking a bot or a "synthetic user" (🙄) to complete a task has become infinitely easier in recent months, but unless those bots are your users, you're only adding a new, equally ambiguous column to the "Tagger Agreement" heat map above.
After Tagging
For some projects, getting the taxonomy and tagging strategy right at launch is not mission-critical. The content collection I'm using as an example in these articles falls into this category. In this case, I'll use data from the traffic and click path analytics and user feedback to help me collect the insight I'll need to iterate and improve the taxonomy and tagging strategy over time.
Indeed, even if you have front-loaded user research with tree testing and usability testing, monitoring a taxonomy's performance and adapting it to new uses and contexts is an ongoing pursuit. This process is called governance, and it is indispensable to maintaining a taxonomy's effectiveness over time.
As with "before tagging" approaches, evidence-based iteration and purposeful governance only work if you actually do them. The care and feeding of a taxonomy is a requirement that catches many organizations new to vocabulary control by surprise. It remains, however, vitally important to ensuring the lasting value of taxonomy and tagging efforts.
Setting Expectations
It would seem, then, that in the absence of front-loaded user research, using an LLM to tag content offers no appreciable advantage over deterministic NLP approaches to auto-categorization. Without user input, neither approach is much more than an exercise in theoretical tag generation.
Since taxonomies are ultimately systems intended to support human behavior in all of its variance and unpredictability, it is hard to imagine an algorithmic approach replacing human creators and maintainers outright. While there certainly appear to be opportunities for automated processes to take some of the tedium and repetition out of this work, it is only by purposefully incorporating the fundamentals of user-centered design that we will achieve results that both "look right" and deliver the outcomes intended for the people who must use them.